Bug Report
Version: v0.0.7
File: src/cortex-engine/src/text_utils.rs
Description
similarity_ratio() computes the Levenshtein distance using character-based iteration (via levenshtein_distance which operates on Vec<char>), but then divides by a.len().max(b.len()) which is the byte length of the strings. For non-ASCII text (CJK, accented characters, emoji), byte length > char count, causing the ratio to be inflated — strings that differ by one character appear more similar than they actually are.
Screenshot
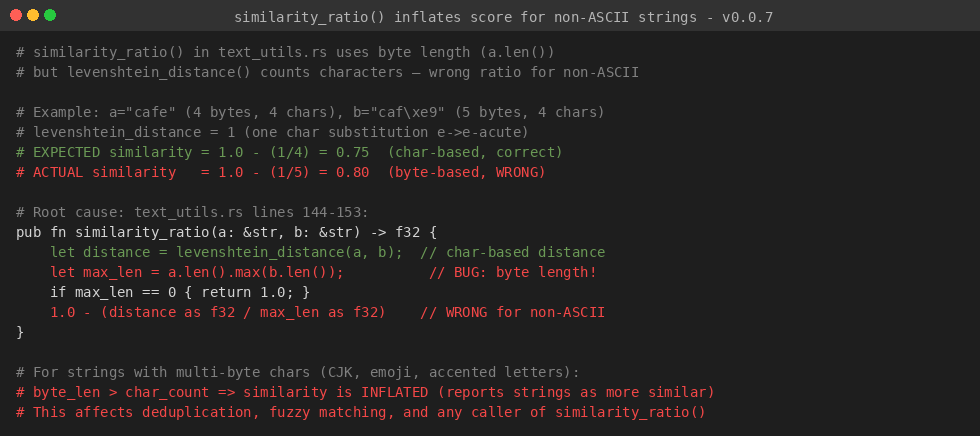
Root Cause
// src/cortex-engine/src/text_utils.rs lines 144-153
pub fn levenshtein_distance(a: &str, b: &str) -> usize {
let a: Vec<char> = a.chars().collect(); // char-based
let b: Vec<char> = b.chars().collect();
// ...computes char-level edit distance...
}
pub fn similarity_ratio(a: &str, b: &str) -> f32 {
let distance = levenshtein_distance(a, b); // char-based distance ✓
let max_len = a.len().max(b.len()); // BUG: BYTE length ✗
if max_len == 0 { return 1.0; }
1.0 - (distance as f32 / max_len as f32) // wrong for non-ASCII
}Example
a = "cafe" (4 bytes, 4 chars)
b = "café" (5 bytes, 4 chars) # é = 2 bytes
levenshtein_distance(a, b) = 1 (one char substitution)
Expected: 1.0 - (1/4) = 0.75
Actual: 1.0 - (1/5) = 0.80 ← INFLATED (byte length = 5 used instead of char count = 4)
For CJK strings (3 bytes/char), the inflation is even larger. A string differing by one character would report similarity close to 1.0 when in fact it differs by 1/N (where N is the char count).
Impact
Any feature using similarity_ratio() for fuzzy matching, deduplication, or ranking will produce incorrect results for non-ASCII agent names, file paths, or user messages containing non-ASCII characters.
Fix
pub fn similarity_ratio(a: &str, b: &str) -> f32 {
let distance = levenshtein_distance(a, b);
let max_len = a.chars().count().max(b.chars().count()); // char count, not byte length
if max_len == 0 { return 1.0; }
1.0 - (distance as f32 / max_len as f32)
}Hotkey: 5CzBkL6CJWFa7QSFoWxqiodobsGmxD6oLxLQa24tNxvsT9dn
UID: 137
Bug Report
Version: v0.0.7
File:
src/cortex-engine/src/text_utils.rsDescription
similarity_ratio()computes the Levenshtein distance using character-based iteration (vialevenshtein_distancewhich operates onVec<char>), but then divides bya.len().max(b.len())which is the byte length of the strings. For non-ASCII text (CJK, accented characters, emoji), byte length > char count, causing the ratio to be inflated — strings that differ by one character appear more similar than they actually are.Screenshot
Root Cause
Example
For CJK strings (3 bytes/char), the inflation is even larger. A string differing by one character would report similarity close to 1.0 when in fact it differs by 1/N (where N is the char count).
Impact
Any feature using
similarity_ratio()for fuzzy matching, deduplication, or ranking will produce incorrect results for non-ASCII agent names, file paths, or user messages containing non-ASCII characters.Fix
Hotkey: 5CzBkL6CJWFa7QSFoWxqiodobsGmxD6oLxLQa24tNxvsT9dn
UID: 137