Визуализации:
- Какво е граф - основни понятия
- Представяне на граф (adjacency matrix, adjacency list, edge list)
- BFS (Breadth First Search)
- DFS (Depth First Search)
- Топологична сортировка
- Практически съвети за задачи
Графът е нелинейна структура от данни, която представлява връзките между отделните елементи на дадено множество. Всеки член на това множество се нарича връх (V), а връзката между два върха се нарича ребро (E).
- Всяко ребро има посока.
- Ако съществува ребро от връх А до връх В, то позволява преминаването само от А към Б.
Пример:

Съществува път от 0 до 4, но не и от 4 до 0.
- Ребрата нямат посока.
- Ако съществува ребро между връх А и връх Б, то позволява преминаването от А към Б и от Б към А.
Пример:

Съществува път както от 0 до 4, така и от 4 до 0.
Граф, чиито ребра имат стойности. Стойностите се интерпретират като тегло, цена, разстояние и т.н. за преместването от един връх до друг по съответното ребро.

- Цикъл - в един граф има цикъл, когато имаме път, който има дължина поне 2 и започва и свършва с един и същ връх.
- Ацикличен граф - граф без цикли.
- Степен (Degree) - брой ребра входящи/изходящи за даден връх.
- indegree - брой входящи ребра
- outdegree - брой изходящи ребра
- Sparse граф - граф с ниска средна стойност на степен на върховете.
- Dense граф - граф с висока средна стойност на степен на върховете.
- Свързаност
- свързан граф - между всеки два върха в графа имаме път.
- несвързан граф - има поне два върха между които няма път.
- т.е. имаме няколко компоненти на свързаност в графа.
- DAG - directed acyclic graph

- В граф може да има цикли.
- Един граф не е задължително да е свързан (т.е. между всеки два върха да има път).
- Дърветата имат йерархична подредба.
- Връзките между върховете се представят чрез булева матрица (А).
- Ако съществува ребро от връх Vi до Vj, клетката Аij = 1.
- Матрицата е симетрична при ненасочен граф.
- Изисква V2 допълнителна памет.
- Позволява константа проверка дали има ребро между два върха.
- Подходящо представяне за dense графи.
Пример:

graph = [
[0, 1, 1, 1],
[1, 0, 1, 0],
[1, 1, 0, 0],
[1, 0, 0 ,0]
]vector<vector<int>> graph = {
{0, 1, 1, 1},
{1, 0, 1, 0},
{1, 1, 0, 0},
{1, 0, 0, 0}
};- Всеки връх съдържа списък с върховете, до които има непосредствени ребра (съседите).
- Ако съществува ребро от връх Vi до Vj, списъкът на съседство на Vi ще съдържа връх Vj.
- Изисква V + Е допълнителна памет.
- Не предоставя константа проверка дали има ребро между два върха (*имплементацията със списък от сетове позволява).
- Подходящо представяне за sparse графи.
- При dense графи, когато E клони към V2, по-подходящо ще е представяне чрез матрица на съседство.
graph = {
'0': set([1, 2, 3]),
'1': set([0, 2]),
'2': set([0, 1]),
'3': set([0])
}// може и unordered_set, зависи дали ни трябва O(1) търсене дали има директен път от един връх до друг (graph[from].find(to))
unordered_map<int, vector<int>> graph = {
{0, {1, 2, 3}},
{1, {0, 2}},
{2, {0, 1}},
{3, {0}}
};- Представяме графа като списък от наредени двойки.
- Често се използва като input за построяване на графа.
- Не е полезен в повечето задачи.
graph = [
(0, 1),
(0, 2),
(0, 3),
(1, 2),
]std::vector<std::pair<int, int>> graph = {
{0, 1},
{0, 2},
{0, 3},
{1, 2},
{2, 3}
};
Note: BFS и DFS на граф надграждат съответните имплементации за дървета, разгледани в тема 7.
Алгоритъм:
- Разделя възлите на посетени и непосетени.
- Започва да обхожда от подаден начален връх.
- Добавя всички съседи, които не са посетени, към края на опашка от върхове за следващо обхождане.
- Взима първия елемент от опашката и повтаря стъпка 3, докато има елементи в опашката.
Свойства:
- Намира най-къс път от даден възел до всички останали в непретеглен граф (всички ребра са с еднаква дължина/ тежест).
- Стои в основата на по-сложни алгоритми като Алгоритъм на Дийкстра.
- O(V + E) сложност по време и O(V) памет заради visited.
Python code
from collections import deque
def bfs(starting_vertex, graph):
q = deque([starting_vertex])
visited = set([starting_vertex])
distance = 0
while q:
print(f"At distance {distance}:")
for _ in range(len(q)):
current = q.popleft()
print(current)
for neighbor in graph[current]:
if neighbor not in visited:
visited.add(neighbor)
q.append(neighbor)
distance += 1
bfs(0, graph)C++ code
void bfs(int starting_vertex, unordered_map<int, unordered_set<int>>& graph) {
queue<int> q;
unordered_set<int> visited;
q.push(starting_vertex);
visited.insert(starting_vertex);
int distance = 0;
while (!q.empty()) {
int level_size = q.size();
cout << "At distance " << distance << ":\n";
for (int i = 0; i < level_size; ++i) {
int current = q.front();
q.pop();
cout << current << "\n";
for (int neighbor : graph[current]) {
if (!visited.count(neighbor)) {
visited.insert(neighbor);
q.push(neighbor);
}
}
}
distance++;
}
}Пример за следния граф:

# Outputs:
At distance 0:
0
At distance 1:
1
2
3
At distance 2:
4
5
At distance 3:
6Алгоритъм:
- Разделя възлите на посетени и непосетени.
- Започва да обхожда от подаден начален връх.
- Добавя всички съседи, които не са посетени, към края на стек* от върхове за следващо обхождане.
- Взима първия елемент от стека и повтаря стъпка 3, докато има елементи в стека.
Свойства:
- Удобен за намиране на компоненти на свързаност, проверка за цикъл в граф и топологична сортировка. (*Забележка: Възможно е и използването на BFS за решаване на горните проблеми.)
- O(V + E) сложност по време и O(V) памет заради visited и стека.
Python code
def dfs(current, visited, graph):
print(current) # 0 1 2 4 5 3 6
for neighbor in graph[current]:
if neighbor not in visited:
visited.add(neighbor)
dfs(neighbor, visited, graph)def dfs_stack(starting_vertex, graph):
stack = [starting_vertex]
visited = set([starting_vertex])
while stack:
print(stack, stack[-1])
current = stack.pop()
for neighbor in graph[current]:
if neighbor not in visited:
visited.add(neighbor)
stack.append(neighbor)C++ code
void dfs(int current, unordered_set<int> &visited, unordered_map<int, unordered_set<int>> &graph) {
cout << current << " "; // 0 3 5 6 4 1 2
visited.insert(current);
for (int neighbor : graph[current]) {
if (!visited.count(neighbor)) {
dfs(neighbor, visited, graph);
}
}
}
void dfsIterative(int start, unordered_map<int, unordered_set<int>>& graph) {
unordered_set<int> visited;
stack<int> s;
s.push(start);
while (!s.empty()) {
int current = s.top();
s.pop();
if (!visited.count(current)) {
cout << current << " ";
visited.insert(current);
for (int neighbor : graph[current]) {
if (!visited.count(neighbor)) {
s.push(neighbor);
}
}
}
}
}Важно е да се отбележи, че горният код работи за 1 компонента на свързаност. Тъй като графът може да не е свързан, трябва да направим "wrapper" функция, която да стартира бфс/ дфс/ броене на компоненти/ намиране на цикъл/ топологична сортировка от всеки връх. Ако върхът вече е бил обходен, не се извиква функцията.
C++ code
int count_areas(const unordered_map<int, unordered_set<int>>& graph) {
int count = 0;
unordered_set<int> visited;
// key - vertex
for (const auto& kvp : graph) {
if (visited.count(kvp.first)) continue;
dfs(kvp.first, visited, graph);
count++;
}
return count;
}
Python code
def count_areas(graph):
count = 0
visited = set()
for vertex in graph:
if vertex in visited:
continue
visited.add(vertex)
dfs(vertex, visited, graph)
count += 1
return countАнимиран пример с друг граф за дфс:


- Подрежда върховете, така че всеки възел се намира преди наследниците си, към които има ребра.
- Работи за DAG (Directed Acyclic Graph).
- Задачата може да се реши чрез DFS или BFS.
За интуиция може да представим връх 2 като Взимане на СДА, за което са нужни връх 1 - взимане на УП и връх 4 взимане на ООП. Връх 3 може да е Бързи Алгоритми, за които са нужни 1, 2 и 4, а 5 и 6 не зависят от СДА и БА - например Джава и Джава за Напреднали, но стъпват на основите на УП и ООП.
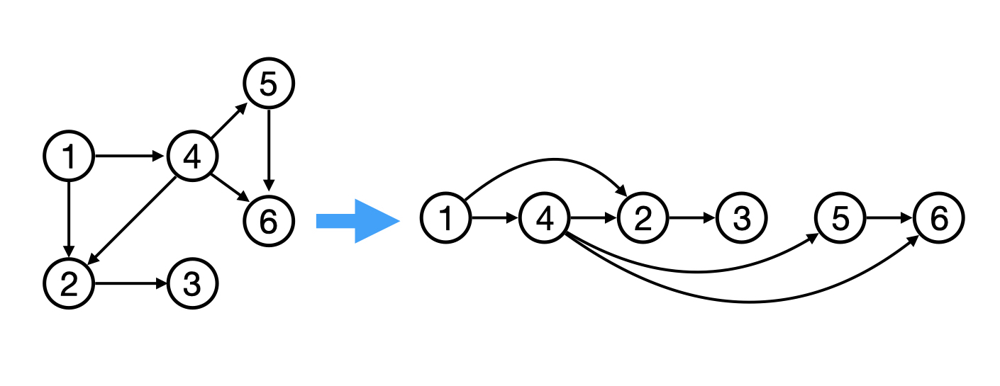
Python code
def topological_dfs(current, stack, visited, graph):
visited.add(current)
for neighbor in graph[current]:
if neighbor not in visited:
visited.add(neighbor)
topological_dfs(neighbor, stack, visited, graph)
stack.append(current)
def topological_sort(graph):
stack = []
visited = set()
for vertex in graph:
if vertex in visited:
continue
topological_dfs(vertex, stack, visited, graph)
stack.reverse()
return stack
topological_sort(graph_topological) # [1, 4, 2, 3, 5, 6]C++ code
void topological_dfs(int current, unordered_set<int> &visited, vector<int> &stack, unordered_map<int, unordered_set<int>> &graph) {
visited.insert(current);
for (int neighbor : graph[current]) {
if (!visited.count(neighbor)) {
topological_dfs(neighbor, visited, stack, graph);
}
}
stack.push_back(current);
}
vector<int> topological_sort(unordered_map<int, unordered_set<int>> &graph) {
vector<int> stack;
unordered_set<int> visited;
for (auto iter = graph.begin(); iter != graph.end(); ++iter) {
int vertex = iter->first;
if (!visited.count(vertex)) {
topological_dfs(vertex, visited, stack, graph);
}
}
std::reverse(stack.begin(), stack.end());
return stack; // 1 4 2 3 5 6
}Друго възможно решение е: [1, 4, 5, 6, 2, 3]. Връщайки се на интуитивния пример Джава и Джава за Напреднали нямат връзка със СДА и БА, така че могат да бъдат разместени като групи.
Трети вариант е: [1, 4, 5, 2, 6, 3].
Тъй като не правим предварителна проверка кой от възлите е с indegree = 0, за да тръгнем от него, алгоритъмът е напълно възможно да започне от връх номер 2. Това няма по никакъв начин да повлияе на правилното завършване на алгоритъма и извеждането на коректна топологична сортировка именно заради втората "wrapper" функция, която пуска topological_dfs за всеки неизследван връх. Също така е напълно възможно да имаме несвързан граф, където топологичните сортировки на всяка компонента трябва да се съставят, но реда им в крайната наредба може да е произволен между тях самите.
Написаният алгоритъм в snippet-а работи само ако сме сигурни, че графът е DAG. В противен случай трябва да използваме някой от следните алгоритми:
- Алгоритъм на Кан
- DFS с маркиране
Може да ги видите като псевдокод тук
И имплементации в Implementations.
Примерни програми с разгледаните алгоритми в Примерите
Имплементация на топологична сортировка с BFS, итеративно DFS и разглеждане на основни проблеми за графи в playground-а. Имплементациите са на Python, но обясненията важат за който и да е език!
Често срещана грешка е да не се затрива глобалната структура, която представлява графа, при наличие на много заявки - един тест с множество графи, за всеки от които трябва да се изведе резултат.
Задачите свързани с графи имат значително по-голям вход от данни, затова може да преговорите и прилагате триковете от HackerrankHacks папката качена в първия семинар. Основните две неща, които ще са ви полезни, са забързването на входа и използването на статична памет.
Практичен пример как влияе забързването на входа - разгледайте решението.
При решаване на задачи с големи графи съществува възможност за увеличаване на ограничението за максимална дълбочина на рекурсията в Python чрез следния код:
import sys
sys.setrecursionlimit(100_000)Невнимателното представянето на граф чрез defaultdict може да доведе до липса на самостоятелните върхове, които не са свързани с нито едно ребро.
- Така граф, който не е свързан, поради наличието на единични самостоятелни върхове, ще изглежда свързан.
- Итерирането през всички върхове на графа може да доведе до RuntimeError: dictionary changed size during iteration, тъй като ще се създаде нов ключ при итерирането през децата на самостоятелен връх.
-
Чрез предварително добавяне на всеки връх. Това може да се случи директно с обикновено dictionary.
graph = {node: [] for node in range(V)}
-
Чрез копирването на ключовете, по които ще итерираме, в отделен списък.
for node in list(graph.keys()): dfs(node, graph)
Пример от решенията.
- Find the town judge
- бонус въпрос: може ли да има двама съдии едновременно?
- Breadth First Search: Shortest Reach
- Find if path exists in graph
- Count of areas
- Cyclic graph
- Course Schedule II
- Clone graph
- All paths from Source to Target
- Премахване на ребра
- Possible Bipartition - Medium
- проверка дали граф е двуделен
- Find the celebrity - Medium