- Executive Overview
- Technical Foundation
- Implementation Guide
- Validation and Evidence
- Security and Privacy
- Future Development
- Appendices
Modern AI assistants (Grok, ChatGPT, Claude, etc.) lack long-term memory between communication sessions. Once a dialogue ends, valuable context is lost, forcing users to repeatedly re-establish their preferences, goals, and personal details in subsequent interactions. This fundamental limitation significantly reduces the efficiency and personalization potential of AI systems.
Existing approaches to this problem have significant drawbacks:
- Cloud storage requires transferring sensitive personal data to third parties, creating privacy and security risks
- Built-in memory of AI systems has inherent limitations (typically restricted to previous messages) and can be deleted by service providers
- Manual re-entry of context demands substantial time investment with each new session, reducing productivity
Personal Context Technology (PCT) enables users to create, manage, and transfer structured personal context data to AI systems with precise instructions for how the AI should use this information. This approach provides personalization and long-term memory between sessions without requiring cloud-based storage or relying on the AI system's internal memory capabilities.
Key elements of PCT include:
- Structured data formats (JSON, YAML, XML, etc.)
- Mandatory instruction blocks that guide AI behavior
- Flexible storage options (local, cloud, or corporate)
- Various transfer methods (paste, file attachment, API, secure links)
-
Addressing the lack of long-term memory in AI chats:
- Comprehensive preservation of relevant context between sessions
- Substantial time savings compared to manual context re-entry
-
Flexibility in using various data formats:
- Support for multiple structured data formats that AI can process
- Compatibility with various AI systems
-
Increased user control over data:
- Choice of storage location (local/cloud)
- Ability to selectively provide information to AI
- Management through instruction blocks
-
Improved recommendation relevance:
- More targeted answers through contextual personalization
- Reduction in the need for repeated clarifications
-
Time efficiency:
- Significant time savings for active AI users
- More concise dialogues while maintaining response quality
Implementation of this technology may impact several key areas:
-
AI assistant market
- Increased interaction efficiency due to continuous context
- Growth in AI assistant usage due to personalization
- New category of "personal AI" with long-term memory
-
Corporate sector
- Reduction in loss of corporate knowledge when employees change
- Improved training efficiency for new employees
- Potential productivity improvements for knowledge workers due to more accurate recommendations
-
Personal data market and privacy
- Shift from cloud data storage to local/hybrid approaches
- Development of tools for encrypting and managing personal data
- Potential reduction in risk of data leaks through storage decentralization
-
Technology startups
- Creation of startups around the personal context ecosystem
- Opportunity for venture capital investment in this emerging field
- Potential for innovation in personalized AI applications
-
Education and human capital
- Improvements in education efficiency through personalized context
- Potential reduction in continuing education costs
- Development of new specialized roles in context management
This technology relates to information technologies, specifically to personalizing interaction with AI assistants through structured data with an instruction management mechanism. The solution aims to eliminate a fundamental limitation of modern AI systems — the lack of long-term memory between communication sessions.
The foundation of PCT is the combination of structured user data with mandatory instruction blocks. Instructions define how AI should interpret, process, and update the data, providing clear guidelines for personalization.
PCT supports various data formats that AI systems can process, including:
- JSON and YAML for general purposes
- XML for complex hierarchical data
- Graph structures for relationship-based information
- Relational data for tabular information
The mandatory instruction block contains four key components:
- Primary instructions: Core guidelines for how AI should use the data
- Update rules: When and how the data should be modified
- Access parameters: Which fields are private/public
- Interaction protocol: Specific communication rules
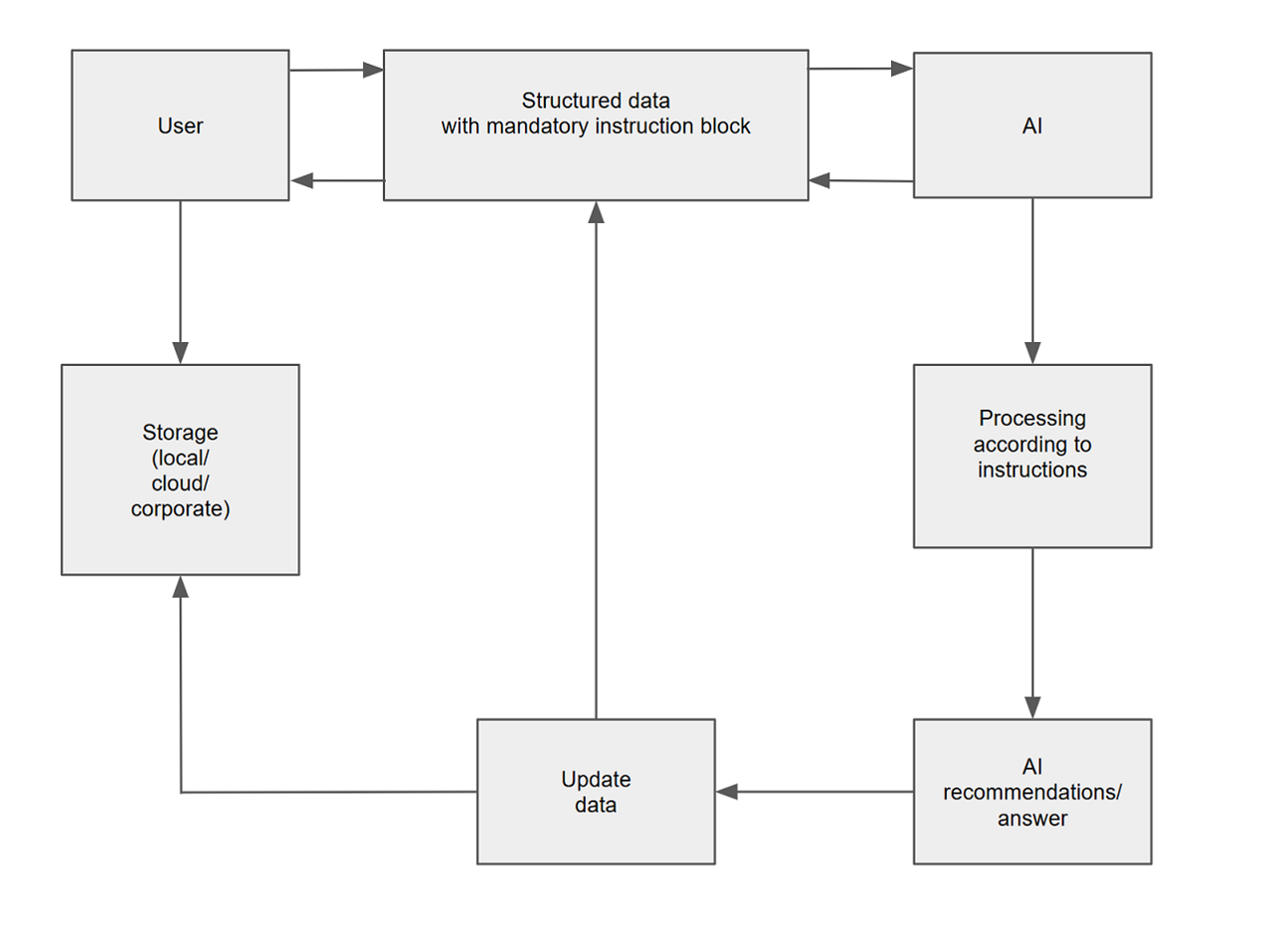
The method includes the following steps:
-
Forming structured data with instructions
The user creates structured data in any format that AI can process, with a mandatory instruction block. The data may contain:
- Basic information (name, age, location)
- Professional information (skills, experience, projects)
- Preferences (communication, formats)
- Interests and goals (professional, personal)
- Schedule and plans
- Metadata (creation date, version, change history)
The mandatory instruction block contains:
- Primary instructions (how to use the data)
- Update rules (when and how to modify data)
- Access parameters (which fields are private/public)
- Interaction protocol (specific communication rules)
-
Choosing data storage
The user chooses how to store structured data with instructions:
- Local storage on the user's device
- Secure cloud storage with controlled access
- Corporate storage with a multi-level permission system
- Temporary storage (only for the duration of interaction)
When choosing cloud or corporate storage, the following can be configured:
- Encryption level
- Access rights for other users
- Authentication and authorization parameters
- Backup and synchronization policies
-
Transferring data with instructions to AI
The user transfers structured data with instructions in one of the following ways:
- Inserts text/code into the chat
- Attaches a file to the chat
- Sends through API
- Provides a link to storage with configured access
This approach significantly reduces context transfer time compared to manually recreating context. Data can be transferred in full or selectively based on access instructions.
-
Processing data and instructions by artificial intelligence
AI analyzes the received structured data, guided by instructions:
- Reads the data structure according to its format
- Applies rules defined in the instructions
- Preserves context from past sessions
- Recognizes data versioning (if applicable)
- Complies with private field access restrictions
- Forms responses based on available data and instructions
- Suggests updates according to rules in the instructions
-
Updating structured data
The user or authorized system makes changes to structured data:
- Applies updates recommended by AI
- Adds new data manually
- Includes metadata about the update (time, source)
- Can version changes
- Updates access rights if necessary
- Saves the version in the selected storage
-
Repeating the interaction cycle
The process continues in new sessions:
- Updated version of data is transferred during a new session
- AI receives the full context from previous interactions
- Volume of repeated explanations is substantially reduced
- Relevance and personalization of responses are increased
- Continuity of interaction between sessions is ensured
-
Compared to cloud storage:
- Flexible storage choice: local or cloud
- Complete control over the choice and volume of data
- Possibility of local encryption before transfer
- Independence from a specific AI provider
-
Compared to built-in AI memory:
- Extended data capacity compared to message-based history
- Independence from the AI provider (compatibility with any AI)
- Resilience to history clearing or system failures
- Ability to structure and categorize data
-
Compared to manual context:
- Significant time savings per session
- Structured and accurate information
- Consistency of data between sessions
- Ability to update data based on conversation results
-
Unique advantages:
- Instructions as the key management mechanism
- Support for any data formats processed by AI
- Multi-format and platform independence
- Possibility of corporate application with access control
A user creates a personal_context.json file:
{
"basic_info": {
"name": "Alexander",
"age": 32,
"location": "Moscow, Russia"
},
"professional_info": {
"occupation": "programmer",
"level": "middle",
"skills": ["JavaScript", "React", "MongoDB"]
},
"health": {
"physical_activity": "running, 3 times a week"
},
"goals": {
"career": "developing ML/AI skills",
"personal": "learning English"
},
"instruction": {
"primary": "Use this context when answering my questions",
"context_update": "If you learn new information, suggest adding it to the appropriate section",
"privacy": "Professional information is public, health is private"
},
"metadata": {
"version": "1.0",
"last_updated": "2025-03-16",
"storage": "local"
}
}The user pastes this JSON into a chat with AI. The AI analyzes the data according to instructions and responds:
"Hello, Alexander! Considering your goal of developing ML/AI skills and your current stack (JavaScript, React), I recommend adding a Python course to your learning plan, as it is the primary language for ML/AI. According to research, a combined learning approach increases effectiveness by 20-30%.
I suggest updating your context:
"goals": {
"career": "developing ML/AI skills, learning Python",
"personal": "learning English"
"update_info": "added Python learning (updated by Claude 3.7, 2025-03-16)"
}
In the next session, the user transfers the updated JSON, and the AI "remembers" the previous recommendation, continuing work from the same point without needing to explain the context again.
A company implements a system of personal contexts for a development team with a multi-level access system:
# team_context.yaml
basic_info:
company: "InnoSoft"
department: "R&D"
team_lead: "Dmitry Nikolaev"
team_members:
- name: "Pavel Smirnov"
position: "Senior Developer"
projects: ["Project Beta", "Cloud Infrastructure"]
access_level: 2
- name: "Elena Sokolova"
position: "Middle Developer"
projects: ["Project Beta"]
access_level: 1
- name: "Andrey Volkov"
position: "Junior Developer"
projects: ["Testing", "Documentation"]
access_level: 1
projects:
Project Beta:
deadline: "2025-06-30"
status: "in development"
critical_tasks:
- "Microservices architecture"
- "Cluster optimization"
notes: "Priority project, investor demonstration in July"
Cloud Infrastructure:
deadline: "2025-05-15"
status: "finalizing"
remaining_tasks:
- "Monitoring"
- "Documentation"
instruction:
primary: "Use this context for answers about team projects"
context_update: "Add new data to the appropriate sections with source indication"
access_control:
level_1: ["basic_info", "team_members", "projects.*.deadline", "projects.*.status"]
level_2: ["projects.*.critical_tasks", "projects.*.remaining_tasks"]
level_3: ["projects.*.notes", "instruction.access_control"]
storage:
type: "encrypted_cloud"
provider: "EnterpriseSecureCloud"
encryption: "AES-256"
backup_frequency: "daily"
metadata:
version: "2.1"
last_updated: "2025-03-15"
updated_by: "D.Nikolaev"
change_history:
- date: "2025-03-15"
source: "Team Meeting"
changes: "Added new team member: Andrey"The corporate AI system receives the YAML via API with authorization and checks the user's access level. The team leader with access level 3 receives complete information, including private notes, while junior developers see only basic information and public project data.
A user creates a graph structure in DOT format to visualize connections between goals and tasks:
digraph PersonalContext {
// Basic information
User [label="Irina\nDesigner, 28 years old", shape=box];
// Goals
Goal1 [label="Master UX Research", shape=ellipse, color=blue];
Goal2 [label="Freelance projects", shape=ellipse, color=blue];
Goal3 [label="Healthy lifestyle", shape=ellipse, color=green];
// Tasks
Task1 [label="Complete UX course", shape=rectangle];
Task2 [label="Create portfolio", shape=rectangle];
Task3 [label="Register on freelance platforms", shape=rectangle];
Task4 [label="Yoga twice a week", shape=rectangle];
// Connections
User -> Goal1;
User -> Goal2;
User -> Goal3;
Goal1 -> Task1;
Goal2 -> Task2;
Goal2 -> Task3;
Goal3 -> Task4;
// Instruction subgraph
subgraph cluster_instructions {
label="Instructions";
Instructions [label="1. Use for planning\n2. Add connections with progress indication\n3. Track deadlines", shape=note];
}
}
The AI processes this graph structure, visualizes it, and recommends an action plan to achieve goals according to the instructions. After discussion, the graph structure is updated:
// Adding progress and new connections
Task1 -> Progress1 [label="Started, 35%\nUpdated: Claude 3.7, 2025-03-16"];
Task4 -> Progress2 [label="Found yoga studio\nStart: 2025-03-22"];
This example demonstrates the flexibility of the method when working with graph data, which can be more visual for planning interconnected goals and tasks.
A user creates the main context in JSON, but uses specialized formats for individual parts:
- Basic information:
context.json - Charts and diagrams: DOT files
- Tabular data: CSV files
- Instructions: a unified YAML file
# instructions.yaml
primary: "Use data from all associated files"
files:
- path: "context.json"
type: "basic_info"
update_rules: "manual_only"
- path: "project_plan.dot"
type: "planning"
update_rules: "suggest_new_nodes"
- path: "learning_progress.csv"
type: "education"
update_rules: "append_only"
privacy:
public: ["basic_info.name", "basic_info.professional"]
private: ["education.grades", "planning.personal"]
sync:
devices: ["desktop", "mobile", "tablet"]
method: "encrypted_cloud"
last_sync: "2025-03-16T15:30:00Z"When interacting with AI, the user transfers instructions.yaml and links to the other files. The AI follows instructions for accessing, processing, and updating each file according to its format and update rules, while maintaining the integrity of the entire context.
Based on the implementation examples provided in the original document, the following best practices can be derived:
-
Context Design
- Organize data in logical categories (basic info, professional info, goals, etc.)
- Include clear, specific instructions for the AI
- Incorporate metadata for version tracking
-
Privacy Protection
- Clearly mark private sections in instructions
- Consider using local storage for sensitive information
- Implement access controls in corporate settings
-
Effective Instructions
- Be specific about how AI should use the data
- Define clear update rules
- Include privacy guidelines
-
Regular Updates
- Maintain version history
- Document update sources
- Include timestamps for all changes
The original document states: "We are developing a comprehensive benchmarking framework to quantify the performance improvements provided by PCM technology. Our preliminary testing indicates substantial benefits in several key areas:
- Context preservation between sessions compared to traditional approaches
- Recommendation accuracy enhancement through contextual personalization
- Response time optimization through efficient context transfer
Detailed benchmarking methodology and results will be published as our testing program progresses. The benchmarking will include controlled comparisons with baseline approaches, documented test cases, and reproducible methodologies."
Personal Context Technology (PCT) is not the only approach to enhancing AI interactions. Below is a comparison with several notable technologies and frameworks as outlined in the original document:
RAG enhances AI responses by retrieving relevant information from external documents in real-time. When a user asks a question, RAG uses semantic search to find pertinent data and incorporates it into the AI's response.
- Difference: RAG focuses on retrieving external knowledge to improve factual accuracy, whereas PCT focuses on long-term personalization by providing a structured user profile. RAG treats a context file as a document to search through, not as an instruction for tailoring responses.
- Use Case: RAG is ideal for fact-based queries, while PCT is better for personalized, user-centric interactions like education.
ChatGPT's memory feature allows the AI to automatically remember details from user conversations. For instance, if a user mentions a preference for visual learning, ChatGPT can recall this in future interactions.
- Difference: ChatGPT's memory is an automatic, server-side feature that collects data during conversations and stores it on OpenAI's servers. PCT, in contrast, is a user-controlled, structured file that the user creates and maintains locally or in a chosen storage location.
- Privacy: PCT prioritizes user control and privacy, as data is not automatically shared with the AI provider, unlike ChatGPT's memory, which requires trust in OpenAI's data handling practices.
DeepMind's approach to personalization involves collecting user data (e.g., search history, interaction patterns) to tailor AI responses. This is often done through machine learning models that adapt to user behavior over time.
- Difference: DeepMind's personalization is an automated, server-side process that relies on continuous data collection. PCT, however, is a manual, user-driven framework where the user explicitly defines their context in a structured file.
- Flexibility: PCT allows users to update their context file at any time, while DeepMind's personalization depends on the system's ability to infer user preferences, which may not always be accurate.
DeepSeek is an open-source AI model focused on research and development, often used for tasks requiring high accuracy and reasoning. It excels in natural language understanding and can be fine-tuned for specific applications, but it does not have a built-in mechanism for long-term user personalization.
- Difference: DeepSeek primarily focuses on improving response quality through advanced training and fine-tuning, rather than maintaining user context across sessions. PCT, on the other hand, is specifically designed to provide a persistent user context, enabling the AI to adapt responses based on user-defined preferences and progress.
- Use Case: DeepSeek is better suited for research or technical queries, while PCT enhances user-specific applications like education.
Grok, developed by xAI, is an AI designed to assist users in understanding complex topics, with a focus on truthfulness and helpfulness. It supports long context windows and can process structured data, making it compatible with PCT.
- Memory Feature: As of April 2025, Grok has introduced a native memory feature that enables it to remember details from past conversations with users, providing more personalized responses based on user preferences and interaction history. This feature includes user controls for transparency, allowing users to see what Grok remembers and choose what to forget.
- Difference from PCT: While Grok now has built-in memory similar to ChatGPT and Gemini, PCT offers different advantages including structured data formats, explicit instruction blocks, user-controlled storage options, and platform independence.
- Complementary Potential: PCT could complement Grok's native capabilities by providing more structured and explicit control over personalization parameters, while leveraging Grok's ability to handle long context windows.
The original document mentions several security-related aspects of PCT:
-
Storage Options
- Local storage on the user's device
- Secure cloud storage with controlled access
- Corporate storage with a multi-level permission system
- Temporary storage (only for the session period)
-
Access Control
- Field-level privacy settings
- Multi-level access privileges (as demonstrated in Example 2)
- Access control through instruction blocks
-
Encryption
- The corporate example mentions AES-256 encryption
PCT has several privacy-enhancing features mentioned in the original document:
-
User-Controlled Storage
- Data remains under user control
- Options for local storage to prevent unauthorized access
-
Selective Data Sharing
- The instruction block can specify which fields are private/public
- Users can choose what information to include in the context file
-
No Automatic Data Collection
- The system relies on explicitly provided data, not automatic collection
To ensure the widest possible adoption and prevent monopolization, the original document states that this technology encourages:
-
Open data format standards
- Common schemas for personal context data
- Standardized instruction blocks across different AI systems
- Interoperable update mechanisms
-
Vendor-neutral implementations
- Cross-platform support
- Independence from specific AI providers
- Community-developed extensions and tools
-
Privacy-enhancing features
- Local-first approach to data storage
- Selective sharing mechanisms
- User-controlled encryption
The original document outlines the potential social impact of this technology:
-
Transform daily AI interaction
- Shift from general, impersonal AI responses to deeply personalized interactions
- Form individual "digital assistants" that know the user at a previously unavailable level
- Make personalization a standard expectation rather than a premium feature
-
Change education and work
- Enable personalized educational trajectories based on the learner's full context
- Reduce adaptation time for new tasks and projects through AI contextual memory
- Create new positions like "context curators" and "personal data architects" in large organizations
-
Improve healthcare and personal well-being
- Enhance healthcare efficiency through improved medical context of the patient
- Support disease prevention through continuous analysis of personal data
- Develop new telemedicine models based on contextual information
-
New understanding of privacy
- Rethinking the concept of privacy: from binary (private/public) to a multi-level system with access gradations
- Formation of new social norms regarding which aspects of personal context are appropriate to make available to different AI systems
- Increasing importance of "information hygiene" and regular personal data audits