
Durable RAG - a persistent memory layer for AI agents built on retrieval-augmented generation.



pip install duragfrom durag import Memory
m = Memory()
m.add("Alice loves Python and open source", user_id="alice")
m.add("Alice built Du-RAG", user_id="alice")
history = m.get_all(filters={"user_id": "alice"})
print(history)Du-RAG is the fastest memory library for AI agents. Unlike other libraries that block for 1-2 seconds calling an LLM on every write, Du-RAG stores memories instantly and lets you consolidate in the background.
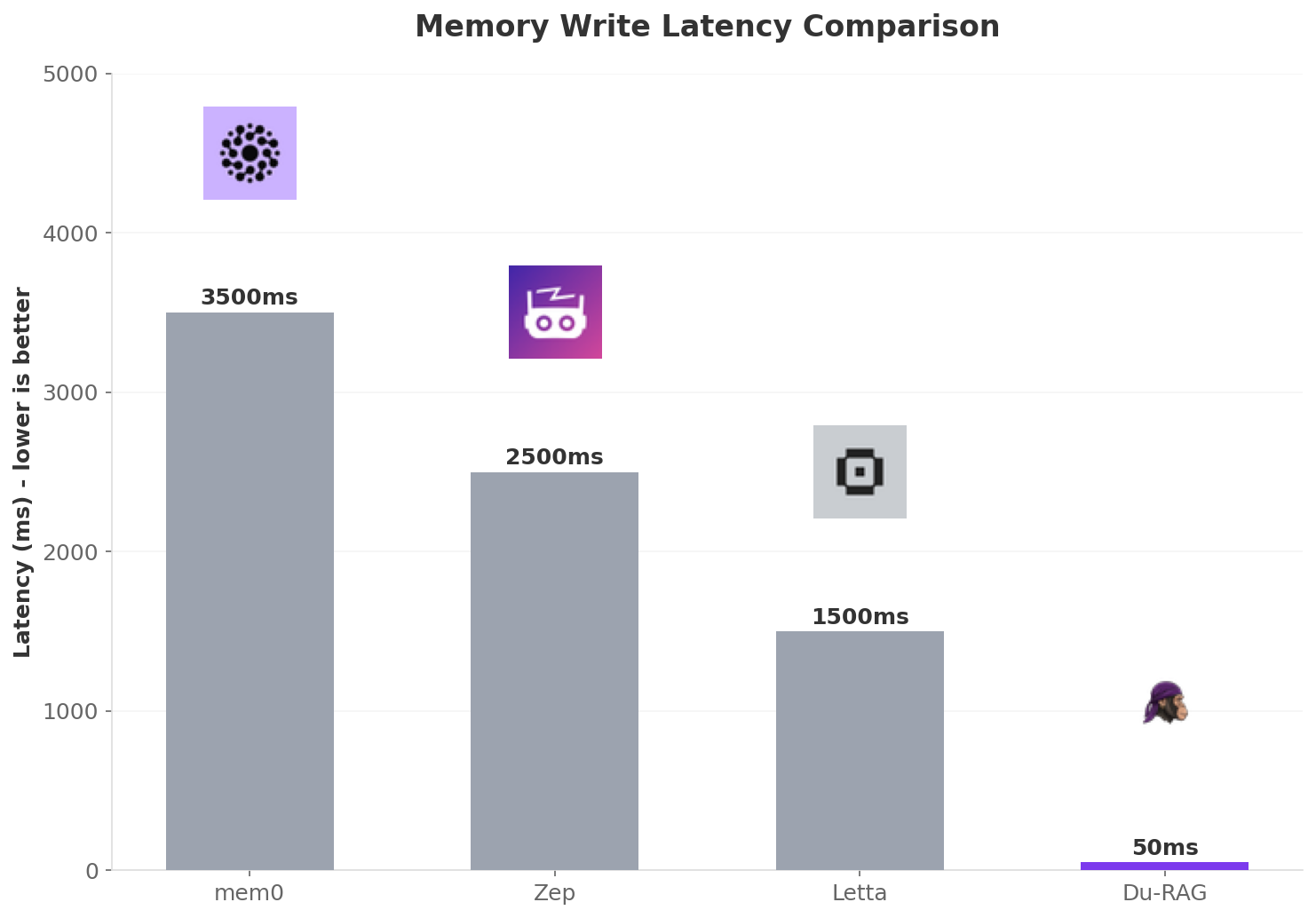
# Fast path - returns in ~50ms, no LLM call
m.add("Alice switched to Enterprise plan", user_id="alice")
# Search works immediately on raw text
results = m.search("What plan is Alice on?", user_id="alice")
# Consolidate later - batch-extract facts with one LLM call
m.consolidate(user_id="alice")Du-RAG requires a provider API key. Set the env var for your preferred provider before first use:
| Provider | Env Var | Used For |
|---|---|---|
| OpenAI (default) | OPENAI_API_KEY |
Embeddings + LLM |
| Anthropic | ANTHROPIC_API_KEY |
LLM |
| Google Gemini | GOOGLE_API_KEY |
Embeddings + LLM |
| DeepSeek | DEEPSEEK_API_KEY |
LLM |
| Together AI | TOGETHER_API_KEY |
Embeddings + LLM |
| Groq | GROQ_API_KEY |
LLM |
| MiniMax | MINIMAX_API_KEY |
LLM |
| Sarvam AI | SARVAM_API_KEY |
LLM |
| vLLM | VLLM_API_KEY |
LLM |
export OPENAI_API_KEY="sk-..."- Fast writes - add() returns in ~50ms (no blocking LLM call)
- Async consolidation - batch-extract facts with consolidate() when idle
- Persistent memory across conversations - agents remember what they learn
- Semantic search via vector embeddings - find the right context fast
- Multiple backends - OpenAI, Anthropic, Gemini, DeepSeek, Ollama, vLLM, and more
- Vector stores - Qdrant (default), FAISS, Chroma, Pinecone, Weaviate, and others
Apache 2.0