fr ASR Backends
🌐 Langue : English | Français
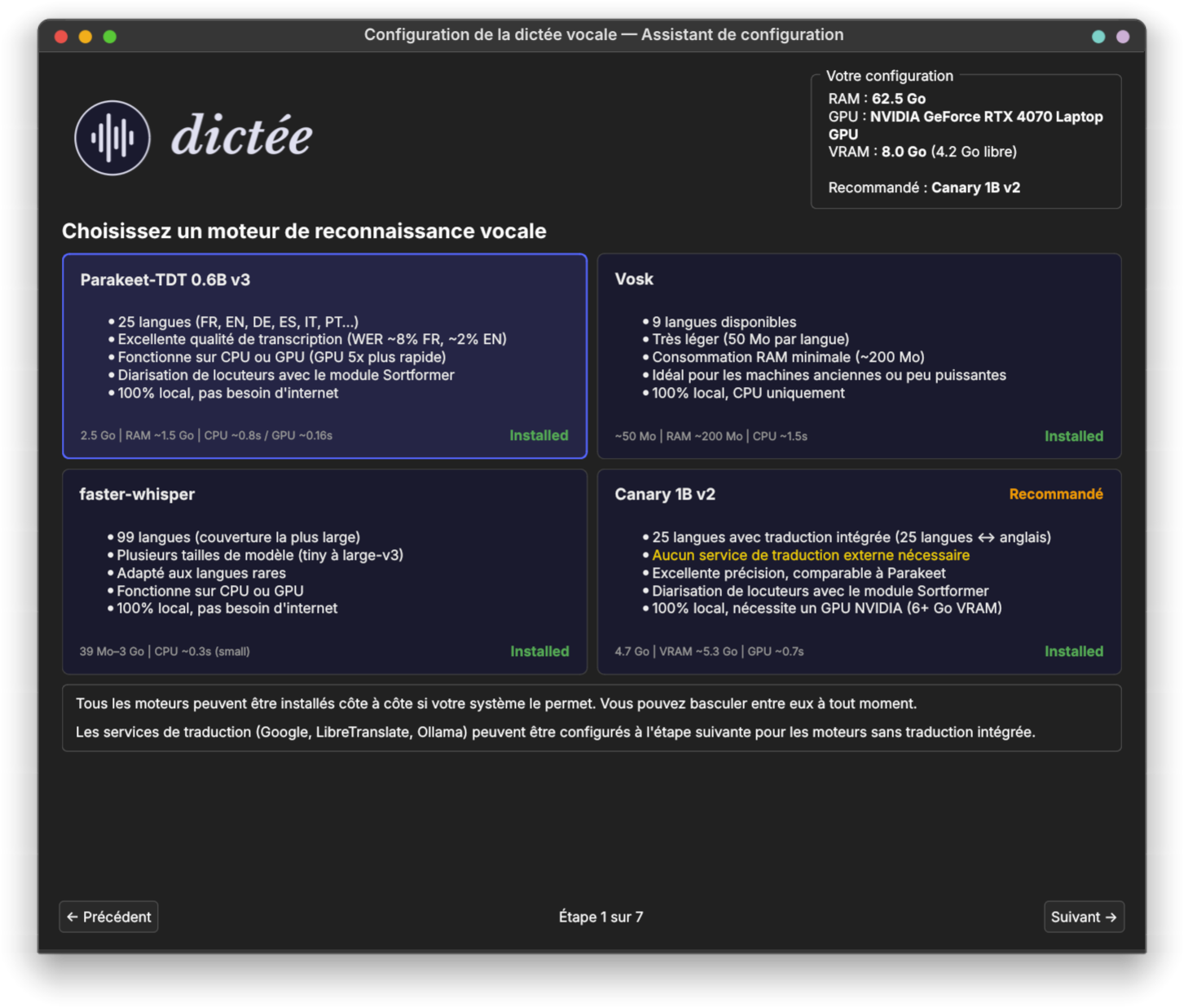
dictée supporte 5 backends de reconnaissance vocale, chacun avec des compromis différents sur précision, couverture linguistique, besoins matériels et capacités de streaming. Le backend par défaut et recommandé est Parakeet-TDT. Un 5e backend — Nemotron — est accessible uniquement en CLI (pour le streaming long format anglais + diarisation).
Le changement de backend est instantané à l'exécution via dictee-switch-backend ou l'assistant de configuration. Tous les backends partagent le même pipeline audio (PipeWire → PulseAudio → ALSA en fallback) et alimentent le même pipeline de post-traitement en 12 étapes.
- Table comparative
- Quel backend choisir
- Parakeet-TDT 0.6B v3 (défaut)
- Canary-1B v2
- faster-whisper
- Vosk
- Benchmarks
- Changement à l'exécution
- Coulisses
| Backend | Langues | Taille | Latence chaude (GPU) | Latence chaude (CPU) | Ponctuation | Traduction intégrée* | Streaming |
|---|---|---|---|---|---|---|---|
| Parakeet-TDT 0.6B v3 | 25 | ~2,5 Go | ~0,16 s | ~0,8 s | ✅ Native | ❌ | ⚠ Fichier seul |
| Canary-1B v2 | 25 | ~5 Go | ~0,7 s | Impraticable | ✅ Native | ✅ (48 paires ↔ EN, même passe forward) | ❌ |
| faster-whisper | 99 | 500 Mo–3 Go | ~0,3 s | ~0,5 s | ✅ Native | ⚠ EN seul (via task=translate) | ❌ |
| Vosk | 20+ | 50 Mo–1,5 Go | N/A | ~1,5 s | ❌ Modèle optionnel | ❌ | ⚠ Capacité modèle, non exposée par dictée |
| Nemotron 0.6B (CLI seul) | 1 (EN) | ~2,5 Go | Streaming | Impraticable | ✅ Native | ❌ | ✅ Natif (chunked) |
* « Traduction intégrée » = traduction effectuée par le modèle ASR lui-même en une seule passe forward. Un ❌ dans cette colonne ne signifie pas que dictée ne peut pas traduire la sortie de ce backend — il indique que le backend ne traduit pas nativement. La traduction est toujours disponible pour tous les backends (Parakeet, Vosk, Whisper…) via l'un des backends de traduction séparés de dictée (Google, Bing, LibreTranslate, Ollama). Voir Traduction.
Latence chaude = temps de la fin de parole à la transcription prête, pour une utterance de 5 s, après que le daemon a chargé le modèle (la latence à froid du premier appel est 2–5× plus élevée).
| Situation | Backend recommandé |
|---|---|
| Dictée quotidienne par défaut (FR/EN/DE/ES/IT/PT/RU/UK + 17 autres) | Parakeet-TDT |
| Besoin de traduction intégrée à la transcription | Canary-1B (25 langues ↔ anglais) |
| Langues exotiques (japonais, arabe, chinois, hindi…) | faster-whisper (99 langues) |
| Ressources minimales (sans GPU, 1 Go RAM, Raspberry Pi…) | Vosk |
| Fichier long anglais + diarisation (réunions, podcasts) |
Nemotron 0.6B via transcribe-stream-diarize (vrai streaming, pas de limite de durée) |
| Streaming / sous-titres en direct dans l'UI de dictée | Aucun backend n'expose pour l'instant les sous-titres en direct dans l'UI principale (le streaming Vosk est niveau modèle seulement ; Nemotron streame mais est CLI-only pour transcription fichier) — prévu pour v1.4+ |
| Précision maximale (en acceptant la latence) | Canary-1B sur GPU |
| Latence minimale | Parakeet-TDT sur GPU |

Parakeet-TDT 0.6B v3 est le modèle Token-and-Duration Transducer de NVIDIA avec un encodeur FastConformer. C'est le backend par défaut depuis la v1.3.
Points forts :
- 25 langues européennes (français, anglais, allemand, espagnol, italien, portugais, néerlandais, ukrainien, russe, polonais, tchèque, slovaque, slovène, croate, bulgare, roumain, hongrois, grec, estonien, letton, lituanien, finnois, suédois, danois, maltais)
- Ponctuation et capitalisation natives (pas besoin de regex de post-traitement pour la sortie de base)
- Excellente précision sur audio réel (WER ~5–8 % sur CommonVoice FR/EN)
- ~0,16 s de latence chaude sur RTX 4070 pour une utterance de 5 s
- Tourne sur CPU (~0,8 s) ou GPU (~0,16 s)
Compromis :
- L'outil en ligne de commande brut
transcribene peut pas traiter d'audio de plus de ~5:20 min sur tout GPU (un bug connu dans le modèle Parakeet-TDT v3).dictee-transcribe(l'interface graphique) contourne ce bug depuis v1.3.4 en découpant automatiquement tout fichier plus long en morceaux plus petits — aucune action manuelle nécessaire. - Impossible de streamer — nécessite l'utterance complète avant de démarrer la transcription
- Pas de traduction intégrée
Approfondissement : Parakeet-TDT-Deep-Dive couvre l'architecture, le détail VRAM, les limites de durée, les défauts connus (premier mot perdu, fausse détection cyrillique), et la fonctionnalité hotwords à venir.

NVIDIA Canary-1B v2 est un modèle attention-encoder-decoder (AED) qui transcrit et traduit en une seule passe.
Points forts :
- 25 langues européennes supportées (même set que Parakeet : EN, FR, DE, ES, IT, PT, NL, UK, RU, PL, CS, SK, SL, HR, BG, RO, HU, EL, ET, LV, LT, FI, SV, DA, MT)
- Traduction intégrée : chacune des 25 ↔ anglais = 48 paires (pas de paires non-anglaises comme FR→DE)
- Précision leader sur les langues supportées
- Ponctuation et capitalisation natives
- Context-aware du décodeur (tokens de prompt pour langue source + cible)
Compromis :
- Nécessite un GPU en pratique (inférence CPU impraticablement lente)
- 5 Go VRAM minimum
- Le hub de traduction est l'anglais (pour FR→DE il faut faire FR→EN puis EN→DE)
- Pas de streaming
Exemple CLI :
# Transcription seule (français)
dictee-switch-backend asr canary
DICTEE_LANG_SOURCE=fr dictee
# Transcription + traduction FR → EN
DICTEE_LANG_SOURCE=fr DICTEE_LANG_TARGET=en dictee --translateL'implémentation Rust de Canary (dans src/canary.rs) a initialement été portée depuis onnx-asr et est désormais entièrement autonome.
faster-whisper est un portage optimisé CTranslate2 de la famille Whisper d'OpenAI, maintenu par SYSTRAN.
Points forts :
- 99 langues (couverture la plus large de tous les backends)
- Plusieurs tailles de modèles —
tiny(39 Mo),base(74 Mo),small(244 Mo),medium(769 Mo),large-v3(1,5 Go),large-v3-turbo(809 Mo),distil-large-v3(600 Mo) - Tourne bien sur CPU comme sur GPU
- Ponctuation et capitalisation natives
- Traduction optionnelle via
task="translate"→ anglais uniquement
Compromis :
- Hallucine sur audio court/silencieux
- Timestamps imprécis sur
large-v3etturbo(DTW dégradé) — continuation par audio-context désactivée - Pas de streaming
Sélection du modèle :
# Dans dictee.conf ou via environnement
DICTEE_WHISPER_MODEL=large-v3-turbo dicteeRecommandé pour usage quotidien : large-v3-turbo (meilleur compromis qualité/vitesse) ou distil-large-v3 (5× plus rapide, ~95 % de la précision de large-v3).
Vosk est un reconnaisseur offline léger basé sur Kaldi, maintenu par Alpha Cephei.
Points forts :
- Modèles tout petits (50 Mo typique, descend à ~40 Mo pour les variantes mobiles)
-
Modèle streaming-capable — l'API Vosk expose
PartialResult()pendant l'enregistrement, mais le daemon de dictée n'appelle actuellement queFinalResult()(transcribe-daemon-vosk:125). L'affichage de texte en direct n'est pas encore exposé dans l'UI. - Tourne sur CPU sans matériel spécial (Raspberry Pi 4 testé)
- Strictement offline — pas besoin de réseau, pas de télémétrie
- 20+ packs langues disponibles sur alphacephei.com/vosk/models
Compromis :
- Pas de ponctuation native sur la plupart des modèles (nécessite post-traitement ou l'add-on
vosk-recasepunc) - Précision inférieure à Parakeet/Canary/Whisper (WER ~15–20 % sur CommonVoice)
- Loterie de sélection du modèle : dictée prend l'ordre alphabétique si plusieurs sont présents (bug connu)
Répertoire des modèles :
ls ~/.cache/dictee/vosk/
# → vosk-model-fr-0.22/
# → vosk-model-small-en-us-0.22/NVIDIA Nemotron-Speech-Streaming-EN 0.6B est un modèle ASR streaming spécialisé, anglais uniquement, conçu pour la transcription long format avec chunking naturel.
Points forts :
- Vrai streaming — traite l'audio en chunks de 10 secondes avec overlap interne ; pas besoin de bufferiser l'utterance complète
- Anglais seul (1 langue)
- Modèle ~2,5 Go (
encoder.onnx+decoder_joint.onnx) - Ponctuation et capitalisation natives
- Pas de plafond de durée dur — peut traiter des fichiers multi-heures avec VRAM bornée
Où il est utilisé :
- Le binaire Rust
transcribe-stream-diarizecouple Nemotron à Sortformer pour la diarisation streaming-friendly de longs fichiers anglais -
Pas exposé via
dictee-switch-backend— vous ne sélectionnez pas « Nemotron » comme backend de dictée - CLI seul : invoqué directement pour la transcription batch, pas pour la dictée interactive
📌 Depuis v1.3.0, le modèle Nemotron n'est plus proposé dans
dictee-setup— le flow UI streaming est parqué jusqu'en v1.4. Le binairetranscribe-stream-diarizeest toujours livré dans les paquets ; les utilisateurs avancés peuvent encore exploiter le pipeline en téléchargeant le modèle manuellement :mkdir -p ~/.local/share/dictee/nemotron cd ~/.local/share/dictee/nemotron for f in encoder.onnx encoder.onnx.data decoder_joint.onnx tokenizer.model; do wget "https://huggingface.co/altunenes/parakeet-rs/resolve/main/nemotron-speech-streaming-en-0.6b/$f" doneLe branchement UI interactif (sous-titres live dans dictee-transcribe / dictee-tray) est sur la roadmap v1.4.
Quand l'utiliser :
- Enregistrements longs en anglais (podcast 1h+, conférence, cours) où Parakeet/Canary saturent la VRAM
- Transcriptions multi-locuteurs anglais (pipeline Nemotron + Sortformer)
Compromis :
- Anglais seul — utiliser Parakeet/Canary/Whisper pour les autres langues
- Pas de traduction (combiner avec un autre backend de traduction après transcription)
- Pas câblé dans le daemon / plasmoid / tray — uniquement outil CLI
Exemple CLI :
transcribe-stream-diarize meeting.wav \
--nemotron-model ~/.local/share/dictee/nemotron/ \
--sortformer-model /usr/share/dictee/sortformer/ \
--format=plainVoir Diarization pour les détails du pipeline.
Mesurés sur TUXEDO InfinityBook Pro Gen8 (MK2) — Intel Core i7-13700H, RTX 4070 Laptop 8 Go, TUXEDO OS (kernel 6.17, NVIDIA 590.48.01), utterance de 5 s en français, modèle chaud :
| Backend | Latence GPU | Latence CPU | VRAM GPU | RAM CPU |
|---|---|---|---|---|
| Parakeet-TDT | 0,16 s | 0,8 s | 1,2 Go | 3,1 Go |
| Canary-1B | 0,7 s | 4,5 s | 5,1 Go | 5,8 Go |
| faster-whisper (large-v3-turbo) | 0,3 s | 0,5 s | 2,1 Go | 2,8 Go |
| Vosk (fr-0.22) | N/A | 1,5 s | N/A | 1,9 Go |
Latence à froid (premier appel après démarrage daemon) : ajouter ~2 s pour Parakeet/Whisper/Vosk, ~5 s pour Canary.
Aucun redémarrage nécessaire — le changement de backend est instantané via le helper dictee-switch-backend :
# Afficher les backends actuels
dictee-switch-backend status
# → ASR: parakeet (dictee.service, active)
# → Translate: google (trans)
# Changer l'ASR
dictee-switch-backend asr canary
dictee-switch-backend asr whisper
dictee-switch-backend asr vosk
dictee-switch-backend asr parakeet
# Lister les disponibles
dictee-switch-backend listLe Tray-Icon et le Plasmoid-Widget incluent des sous-menus pour les backends — pas besoin de terminal.
Chaque backend de dictée tourne comme service systemd utilisateur :
| Backend | Unité service | Binaire daemon |
|---|---|---|
| Parakeet | dictee.service |
transcribe-daemon (Rust) |
| Canary | dictee-canary.service |
transcribe-daemon --canary (Rust) |
| Whisper | dictee-whisper.service |
dictee-transcribe (Python, faster-whisper) |
| Vosk | dictee-vosk.service |
dictee-transcribe (Python, vosk-api) |
| Nemotron | (pas de daemon — CLI seul) |
transcribe-stream-diarize (Rust) |
Tous les services écoutent sur le même socket Unix à $XDG_RUNTIME_DIR/transcribe.sock, avec un protocole requête/réponse simple. Un seul service est actif à la fois (les autres sont mutuellement exclusifs via Conflicts= dans leurs unités systemd).
Pour le protocole complet et les internes du daemon, voir Developer-Guide.
- Parakeet-TDT-Deep-Dive — internes du backend par défaut
- Translation — backends de traduction (séparés des backends ASR, bien que Canary combine les deux)
- Post-Processing-Overview — ce qui se passe après la transcription
-
CLI-Reference — tous les flags pour
dictee-switch-backend,dictee-transcribe, binaires Rust