fr Diarization
🌐 Langue : English | Français
La diarisation répond à « qui a parlé et quand ? » dans un enregistrement multi-locuteurs. dictée étiquette chaque tour de parole avec Speaker 0, Speaker 1, … (jusqu'à 4 locuteurs) que tu peux ensuite renommer (Alice, Bob, …) en deux clics.
Deux façons de l'utiliser :
- En direct (mode Meeting) — diariser ce que tu enregistres à la volée, depuis le plasmoid ou le tray.
-
Depuis un fichier — charger n'importe quel audio dans
dictee-transcribeet cocher Diarisation.
La sortie diarisée contourne le post-traitement par design (pas de capitalisation auto, pas de correction LLM) pour préserver les frontières de locuteurs. Pour des compte-rendus polis, lance l'analyse LLM de la diarisation après coup.
- Clique sur le plasmoid dictée (ou l'icône tray) pour ouvrir la popup.
- Clique sur Meeting — dictée prépare le modèle, le bouton devient Start meeting.
- Clique sur Start meeting, parle, puis Stop meeting quand tu as fini.
- Le texte diarisé est collé dans ton app active :
Speaker 1: Bonjour à tous, on commence la réunion. Speaker 2: Merci. On démarre avec la roadmap ? Speaker 1: Oui, je partage mon écran.
En mode Meeting, la popup reste épinglée et le post-traitement / la traduction sont automatiquement désactivés.
Équivalent CLI : dictee --meeting.
- Ouvre
dictee-transcribe(menu Fichier → Ouvrir, ou glisse-dépose un audio sur la fenêtre). - Coche Diarisation (identification des locuteurs).
- (Optionnel) ajuste le slider Seuil — voir l'encart ci-dessous pour comprendre.
- Clique sur le gros bouton violet « Transcrire » à droite.
💡 Comprendre le slider Seuil
Le seuil contrôle deux probabilités internes :
onset— à quel point le modèle doit être certain qu'un locuteur commence à parler avant de marquer une nouvelle frontière.offset— à quel point il doit être certain qu'il s'arrête.
Position Comportement Quand l'utiliser Bas (0-40 %) Seuils plus permissifs → le modèle change de locuteur facilement. Plus de transitions détectées. Audio avec beaucoup de tours rapides, dialogues vifs, voix très distinctes. Au prix : une seule personne peut parfois être découpée en deux locuteurs si sa voix change un peu. 50 % (défaut) Preset CallHome — équilibré, calibré sur conversations téléphoniques. La plupart des cas. Réunions normales, podcasts, interviews. Haut (60-100 %) Seuils plus stricts → le modèle ne change de locuteur que s'il est très sûr. Moins de transitions. Audio bruité, voix similaires (frères, collègues du même âge), ou si tu vois trop de Speaker N qui sont en réalité une seule personne. Risque inverse : deux personnes proches peuvent être fusionnées. Si le résultat ne te plaît pas, change le slider et relance — un nouvel onglet est créé pour chaque essai (le titre indique la valeur, ex.
#2 Diarize 70%), tu peux comparer côte à côte.

Pendant le travail (avec un spinner qui tourne dans le titre de l'onglet), tu peux ouvrir d'autres onglets ou changer de fenêtre — dictée te rendra la main toute seule. Si tu changes d'avis, ferme l'onglet en cours : la diarisation s'annule proprement et libère la GPU.
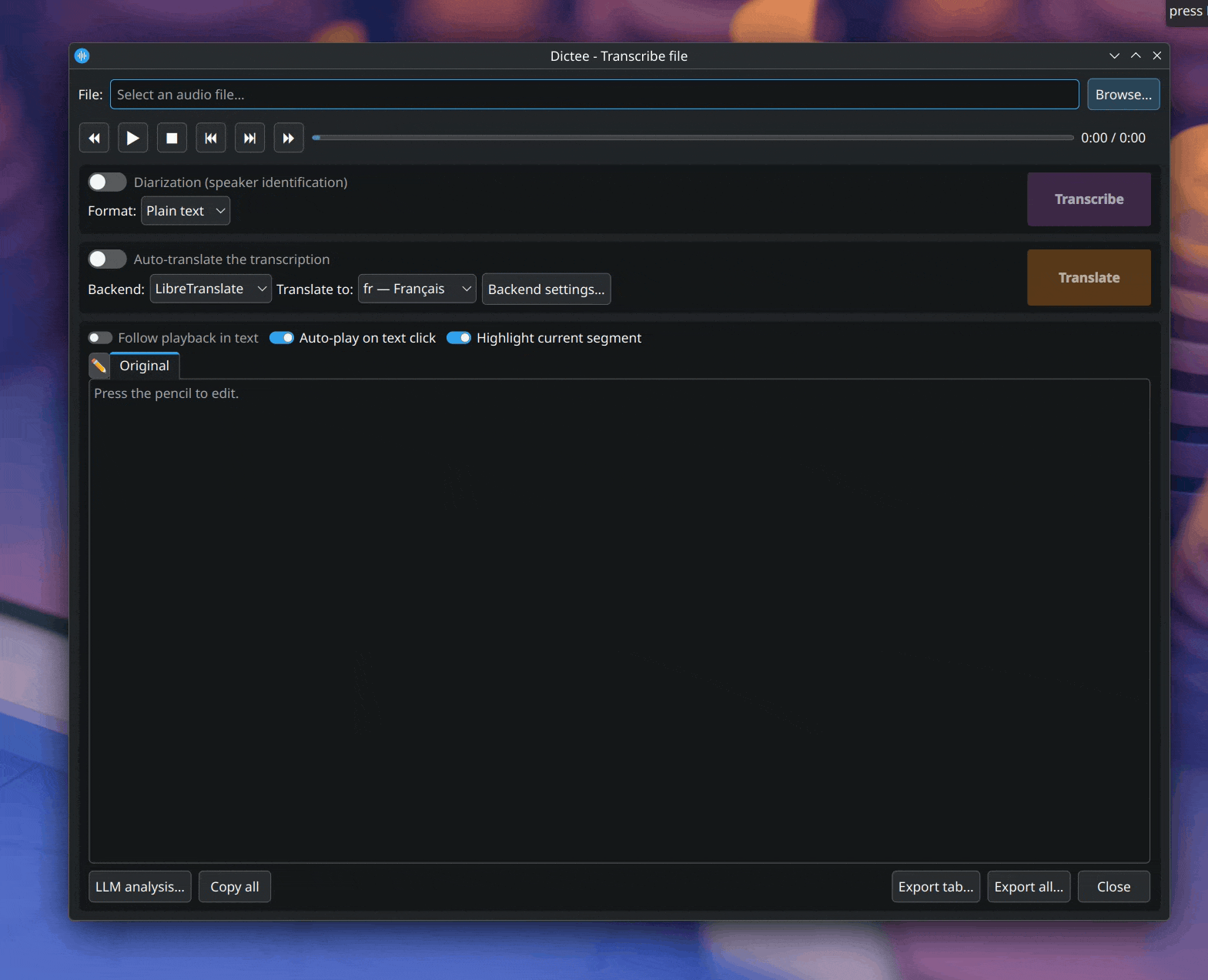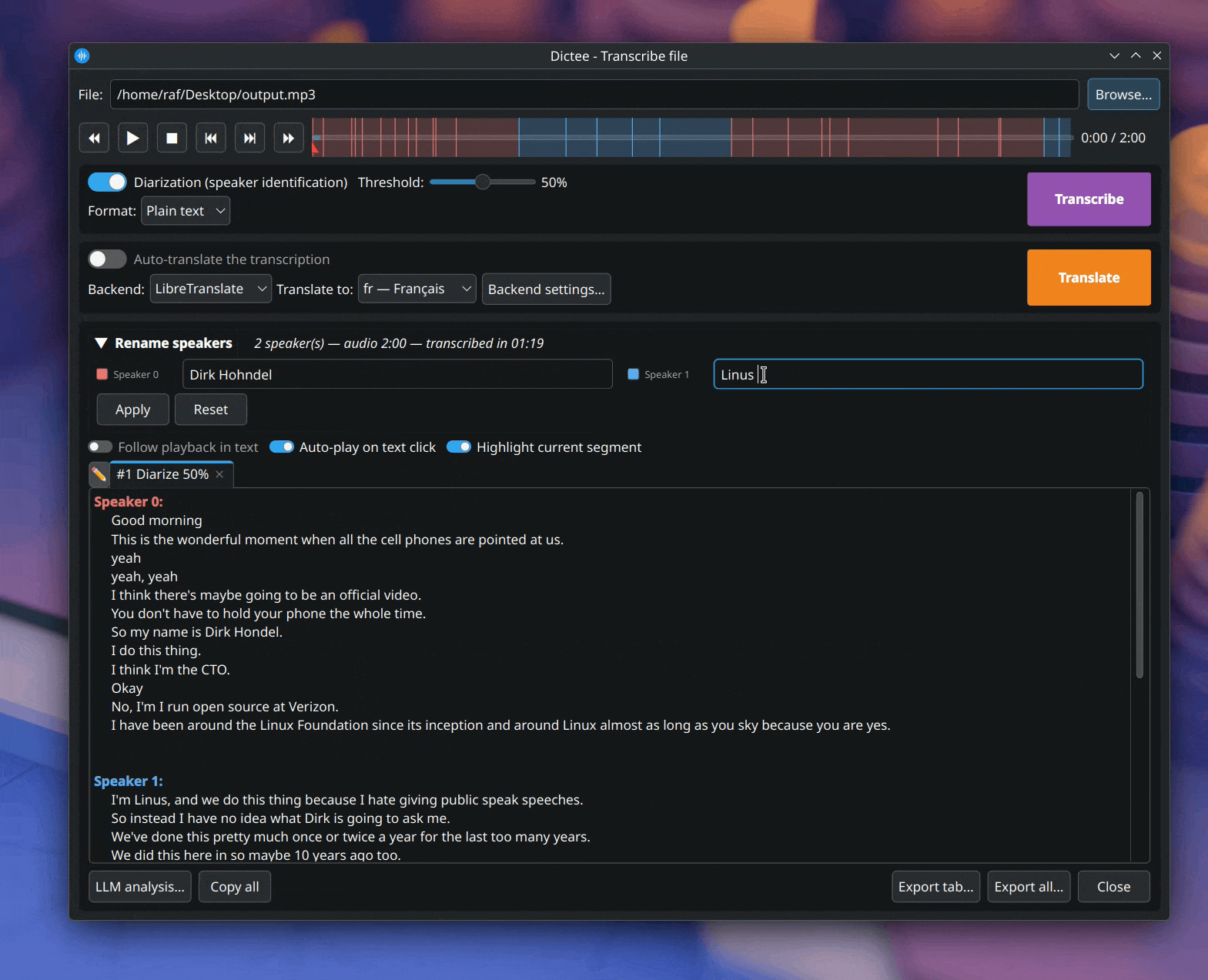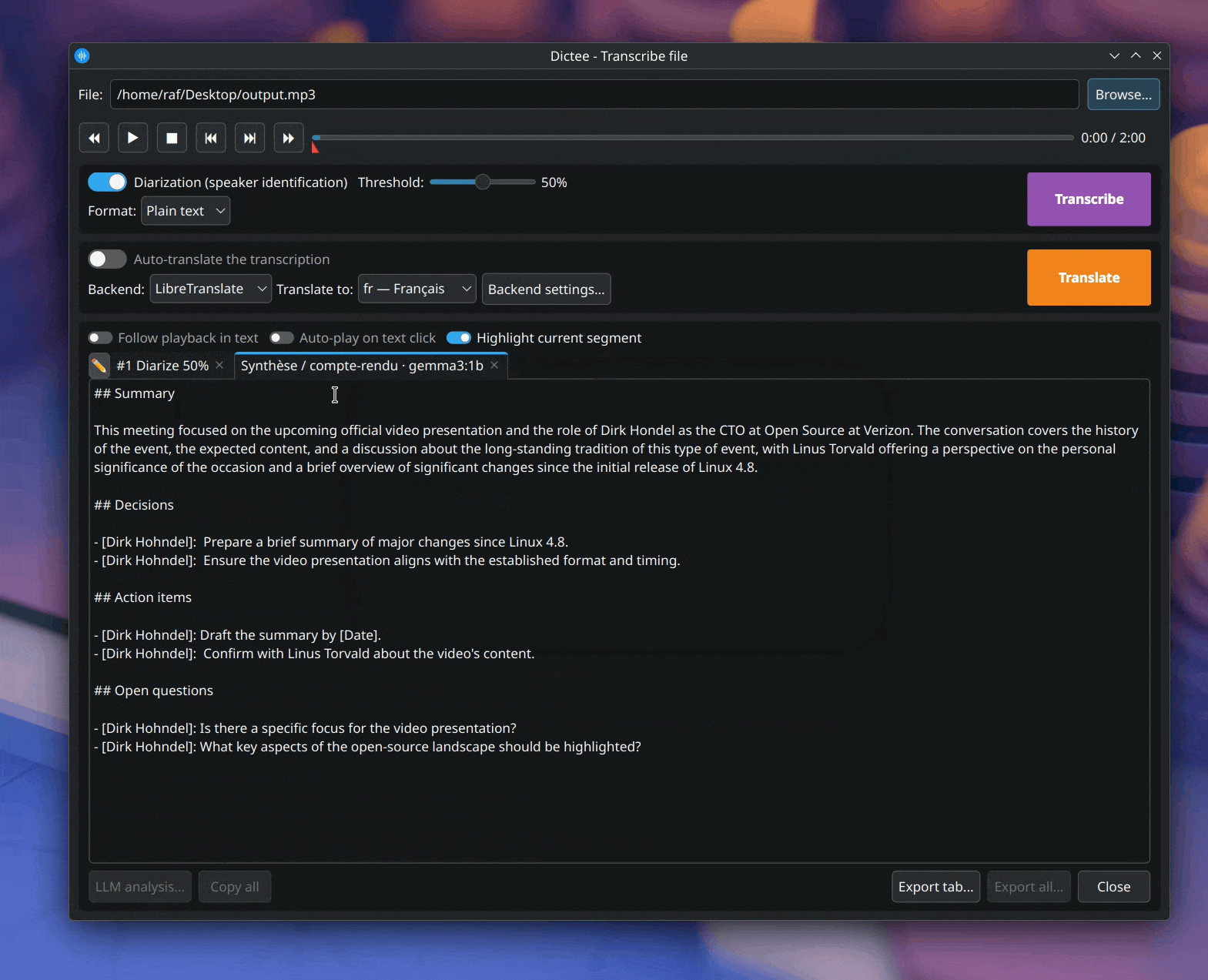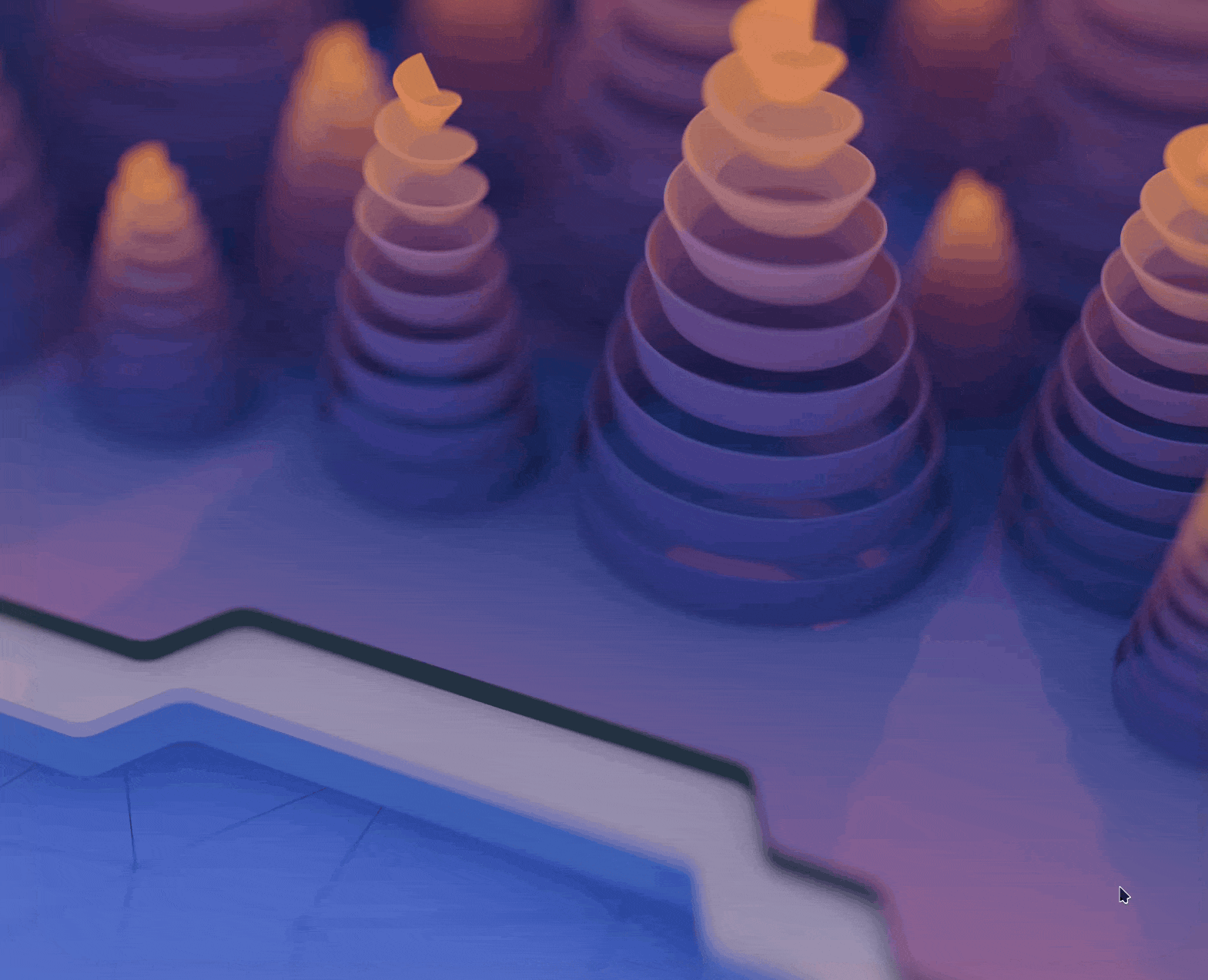
Une fois terminé, tu vois les locuteurs étiquetés à côté de chaque tour de parole, avec une couleur dédiée par locuteur (rouge, bleu, vert, orange) qu'on retrouve aussi sur la timeline du lecteur audio :

- Les bandes colorées sur la timeline montrent quel locuteur parle quand
- Le triangle rouge au-dessus de la timeline indique la position de lecture
- Clique sur les boutons ⏮ / ⏭ (double flèche avec barre) à côté du lecteur pour sauter au segment précédent / suivant — pratique pour rejouer juste un tour de parole
Trois toggles, juste sous l'en-tête de l'accordéon « Renommer les locuteurs », te permettent de lier la lecture audio au texte affiché dans les deux sens. Tous les trois sont mémorisés entre les sessions.

| Toggle | Ce qu'il fait | Quand l'activer |
|---|---|---|
| Suivre la lecture dans le texte | Le curseur de texte se déplace en temps réel pendant que l'audio joue. Tu vois exactement où tu es à mesure que ça parle. | Pour relire à voix lente : tu écoutes, ton œil suit. |
| Lecture auto au clic dans le texte | Cliquer sur n'importe quel segment du texte saute la lecture audio à l'instant correspondant. | Pour vérifier rapidement « ai-je bien dit ça ? » — un clic sur la phrase, l'audio joue. |
| Surligner le segment courant | Le segment dont l'audio est en train de jouer est souligné dans le texte. | Pour ne jamais perdre le fil sur un audio long et dense — l'œil retrouve sa place en un coup d'œil. |
Tu peux les activer indépendamment ou tous ensemble — le combo « Suivre + Surligner » est particulièrement utile pour relire un compte-rendu de réunion en passant en revue chaque tour de parole.
💡 Durée audio : aucune limite. Les fichiers longs (1 h, 2 h, davantage) sont découpés automatiquement en interne. Tu vois la progression chunk par chunk dans le statut.
Juste après la diarisation, un accordéon « Renommer les locuteurs » apparaît, replié, sous les sections Transcribe / Translate. Ouvre-le, tape un vrai nom à côté de chaque pastille de couleur (Speaker 0 → Alice) et clique sur Apply : toutes les vues (texte, timeline, exports) et toutes les futures analyses LLM utiliseront les noms personnalisés. Reset revient aux labels génériques Speaker N.

Le bouton Export… (en bas) propose :
-
Texte brut (
.txt) — un export simpleSpeaker: ligne; -
SRT (
.srt) — sous-titres avec timestamps, prêts pour ta vidéo ; -
JSON (
.json) — segments complets avecstart,end,speaker,text(idéal pour scripts).
Le dialog exporte l'onglet actif — son nom est affiché en haut (Tab : …). Coche un ou plusieurs formats, modifie le préfixe de nom de fichier si tu veux, choisis le dossier de sortie et clique sur Export. Pour exporter un autre onglet (transcription brute, synthèse LLM, etc.), bascule dessus dans la fenêtre principale puis ré-ouvre Export….
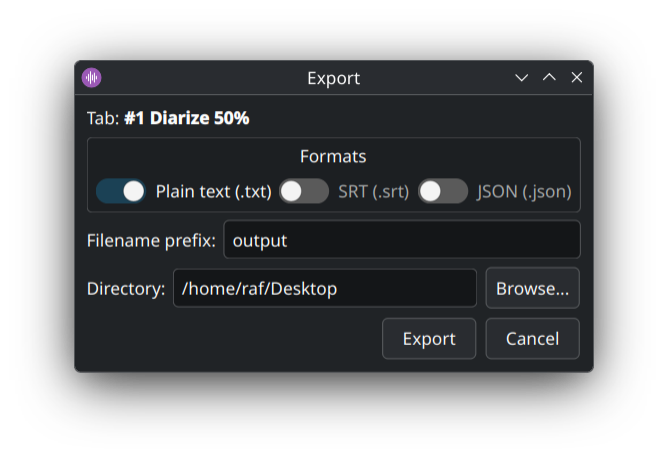
Les noms personnalisés via l'accordéon de renommage sont propagés à tous les formats d'export.
Une fois la diarisation prête (ou la transcription brute si tu n'as pas coché Diarisation), le bouton LLM analysis… s'active sous l'onglet actif. Clique dessus pour ouvrir le dialog :
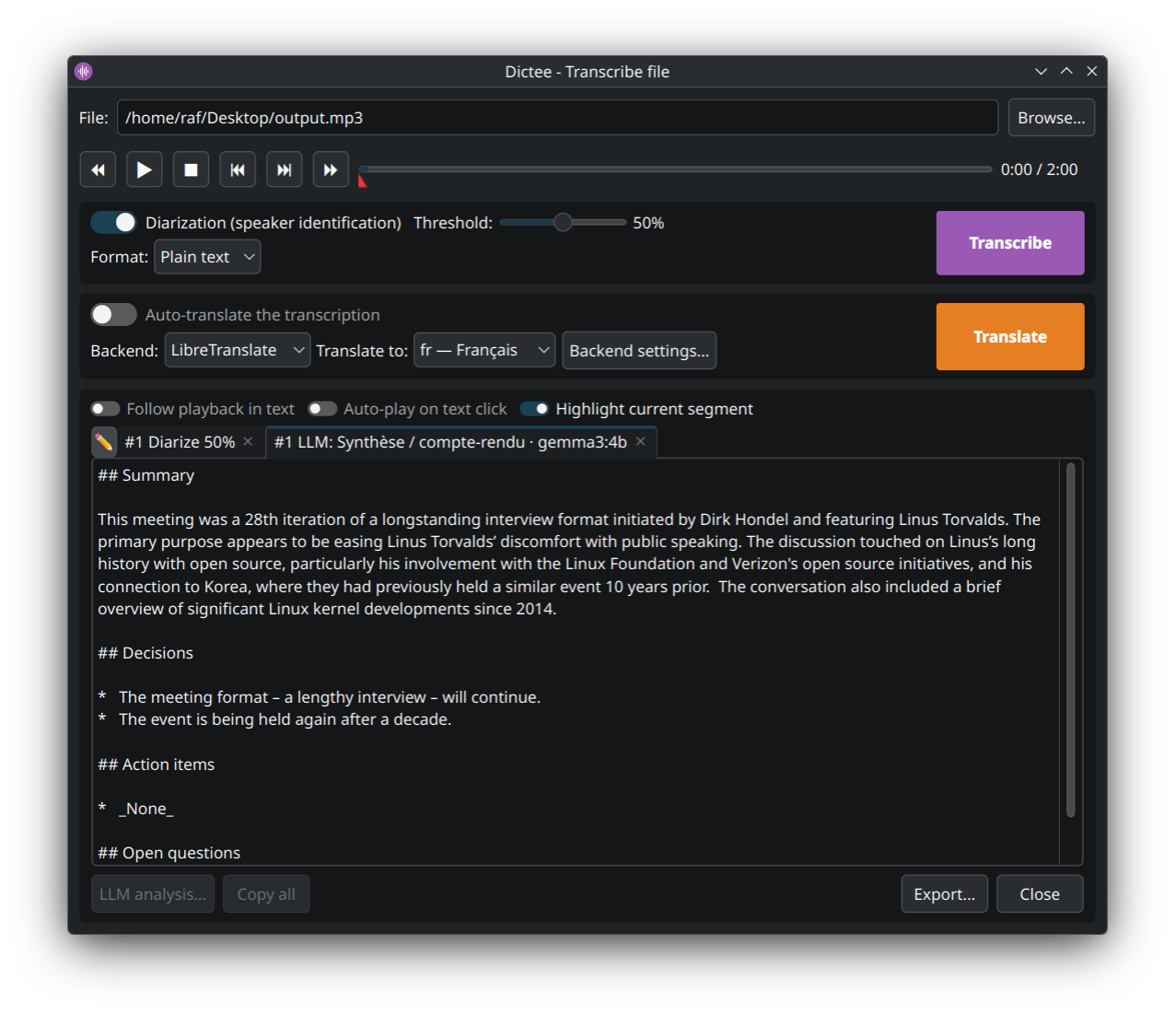
Tu y choisis trois choses :
- Profile — Synthèse / compte-rendu, Chapitrage, Correction ASR contextuelle (built-ins) ou un de tes profils. La liste est filtrée selon le tab : un onglet diarisé ne propose que les profils diarisés ; un onglet brut, que les profils plain text. Édite tes profils via dictee-setup → LLM Diarization → Manage profiles…
- Provider — le serveur LLM à interroger (Ollama, OpenAI, Claude, Gemini, Mistral, DeepSeek, Cerebras, OpenRouter, LM Studio, Jan, vLLM…). Configurés via Manage providers…
-
Model — pré-rempli avec le
default_modeldu profil ; tu peux le surcharger pour ce run uniquement (ex. testergpt-oss:120b-cloudà la place degemma3:4b).
Le résultat tombe dans un nouvel onglet LLM: <profil> · <model> à côté de la transcription, en streaming (tu vois le texte apparaître au fur et à mesure). Le tab original n'est jamais modifié. La sortie est dans ta langue native (DICTEE_LANG_SOURCE), peu importe la langue de l'audio.
Annuler en cours de génération : ferme simplement l'onglet
LLM: …— la requête HTTP est abortée immédiatement (utile pour libérer la VRAM ou stopper un Ollama qui réfléchit trop longtemps).
Sur un onglet LLM, le bouton Export… ouvre un dialog dédié (différent de l'export texte/SRT/JSON de la transcription) :
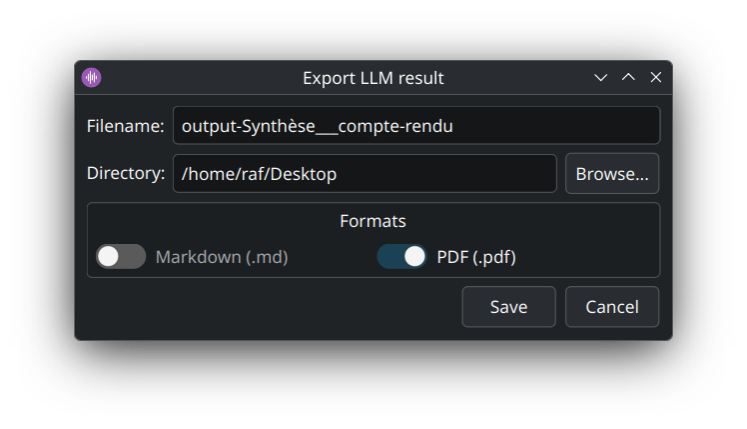
Deux formats :
-
Markdown (
.md) — le LLM produit déjà du Markdown, le fichier est écrit tel quel (idéal pour Obsidian, Joplin, Logseq, GitHub…) ; -
PDF (
.pdf) — rendu via Qt à partir du Markdown : titres, listes, gras, tableaux propres pour partager ou archiver.
Tu peux cocher les deux pour générer les deux fichiers en un clic. Nom de fichier et dossier éditables.
Détails complets (édition des prompts, options par profil, tableau context-window par backend, désactivation du thinking) sur la page Analyse LLM de la diarisation.
- 4 locuteurs max. Au-delà, le modèle en fusionne certains. (Cette limite devrait être levée en v1.4.)
- La qualité audio compte. Bruit de fond fort, voix proches (même âge/genre/accent), tours < ~2 s, ou parole superposée dégradent le résultat.
- Les labels sont anonymes. dictée ne devine pas les vrais noms — utilise l'accordéon de renommage.
- Analyse LLM de la diarisation — Synthèse / Chapitrage / Correction ASR avec ton LLM préféré.
- Pour les développeurs / utilisateurs avancés : fr-dev-Diarization (CLI, VRAM, internals du pipeline chunked, formats de sortie bruts).