fr Configuration
🌐 Langue : English | Français
Cette page est la référence de l'interface dictee-setup. Chaque onglet et sous-section est documenté ci-dessous avec un screenshot et une description courte. Pour les détails conceptuels derrière chaque fonctionnalité, suivez les liens vers les pages dédiées — cette page est un tour d'horizon rapide de la fenêtre de configuration.
dictee-setup est l'unique endroit où chaque option est réglable ; il écrit ses décisions dans ~/.config/dictee/dictee.conf. L'assistant de configuration est le même binaire en mode premier lancement ; cette page couvre le mode sidebar classique que vous obtenez une fois le premier setup terminé.
Nouveau en v1.3.0 — une page dédiée LLM Diarization dans la sidebar permet de gérer les providers LLM et les profils d'analyse (synthèse / chapitrage / correction ASR sur transcriptions diarisées). Tour complet sur la page fr-LLM-Diarization.
- Lancer dictee-setup
-
Backend ASR
- Parakeet-TDT · faster-whisper · Vosk · Canary · Nemotron
-
Traduction
- Google · Bing · LibreTranslate · Ollama · Canary intégré
- Raccourcis clavier
- Microphone
- Retour visuel
- Notifications
- Options
- Post-traitement
- À propos
- Où se trouve le fichier de configuration ?
Quatre points d'entrée, tous ouvrent le même binaire :
| Méthode | Commande / Action |
|---|---|
| Terminal |
dictee-setup (sidebar classique) — dictee-setup --wizard (force l'assistant de première exécution) |
| Menu d'applications | Chercher « Configuration de Dictée » (Paramètres · Accessibilité) |
| Icône tray | Clic droit sur l'icône dictée → Configurer Dictée |
| Widget plasmoid | Clic droit sur le plasmoid dictée → Configurer (KDE Plasma 6) |
La première fois que vous lancez dictee-setup (sans ~/.config/dictee/dictee.conf), l'assistant de configuration guidé s'ouvre automatiquement. Une fois terminé, la même commande ré-ouvre le mode sidebar documenté ci-dessous.
Choisissez le moteur de reconnaissance vocale qui transforme votre voix en texte. dictée fournit cinq backends, chacun affiche ses options propres (variante du modèle, langue, hotwords, VAD, beam size, compute type) dans l'onglet ASR.
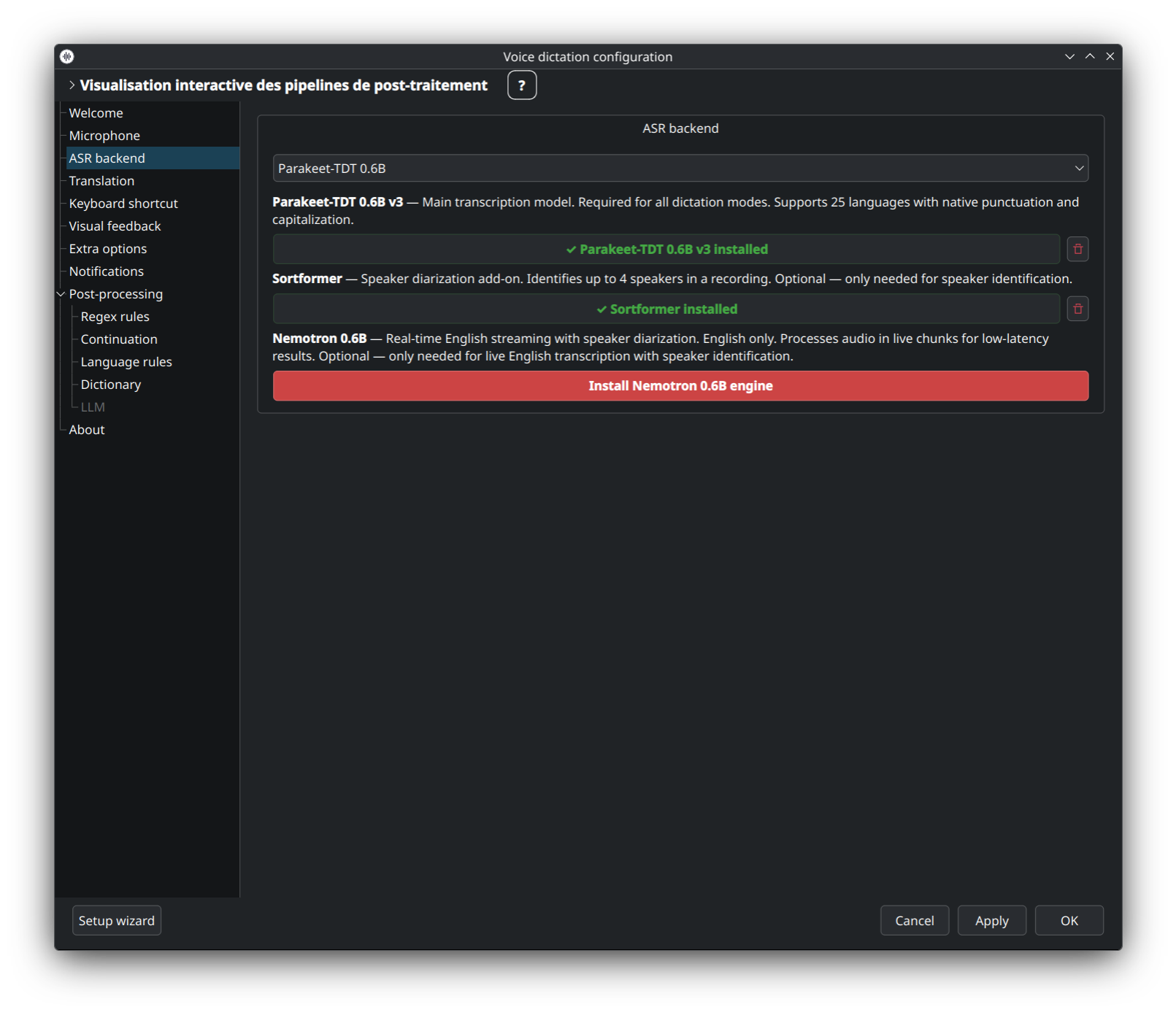
Choix par défaut recommandé — 25 langues, ponctuation + capitalisation natives, meilleure précision sur GPU. Consommation VRAM raisonnable grâce au décodeur TDT (prédiction de durée factorisée). Couvre la plupart des langues européennes + asiatiques.
👉 Détails : Parakeet-TDT-Deep-Dive.
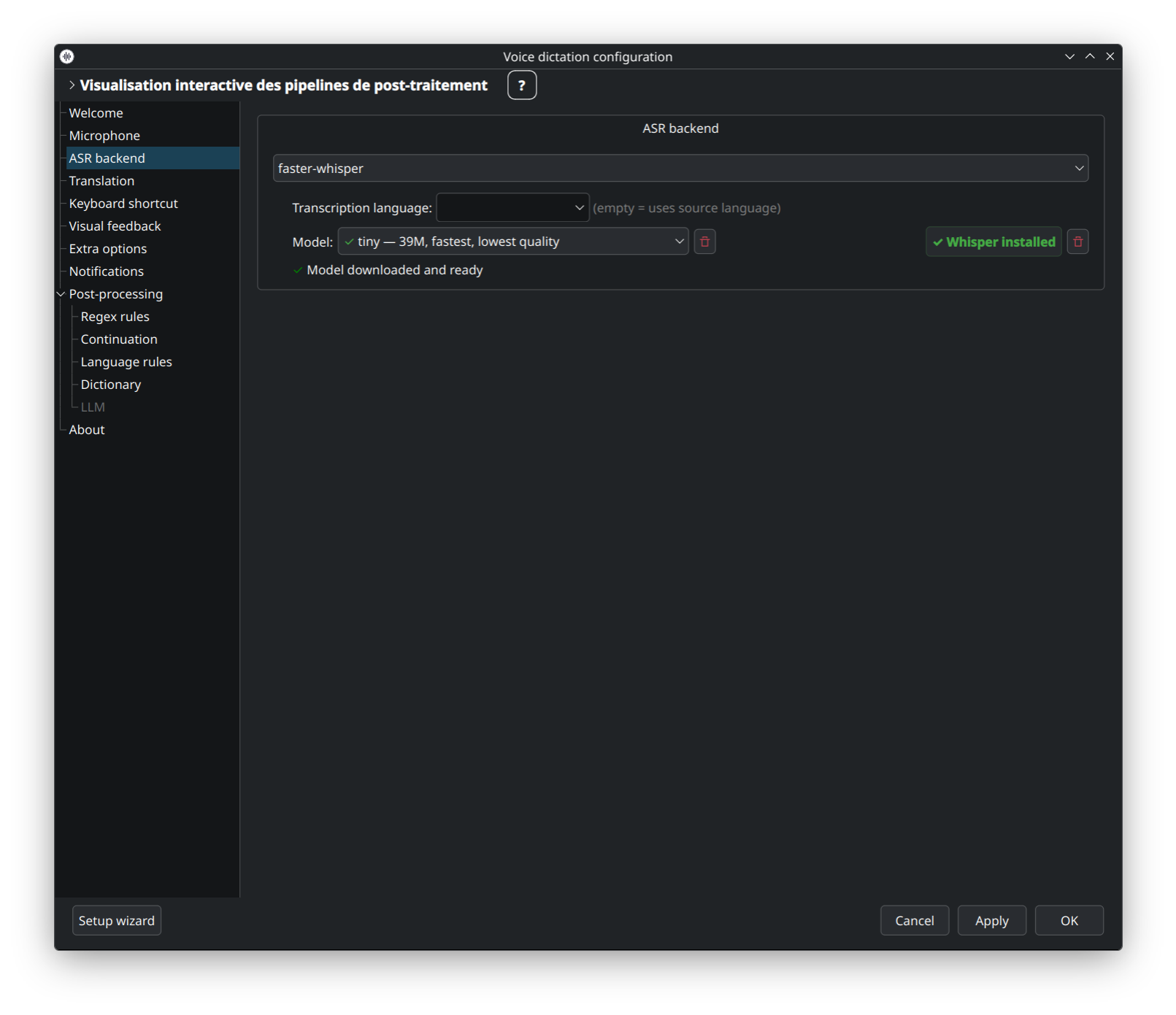
Fait tourner les modèles OpenAI Whisper (tiny → large-v3) en local via ctranslate2. Expose VAD, beam size, hotwords, initial prompt, et compute type (int8 / float16). Parfait pour les langues hors de la couverture Parakeet.
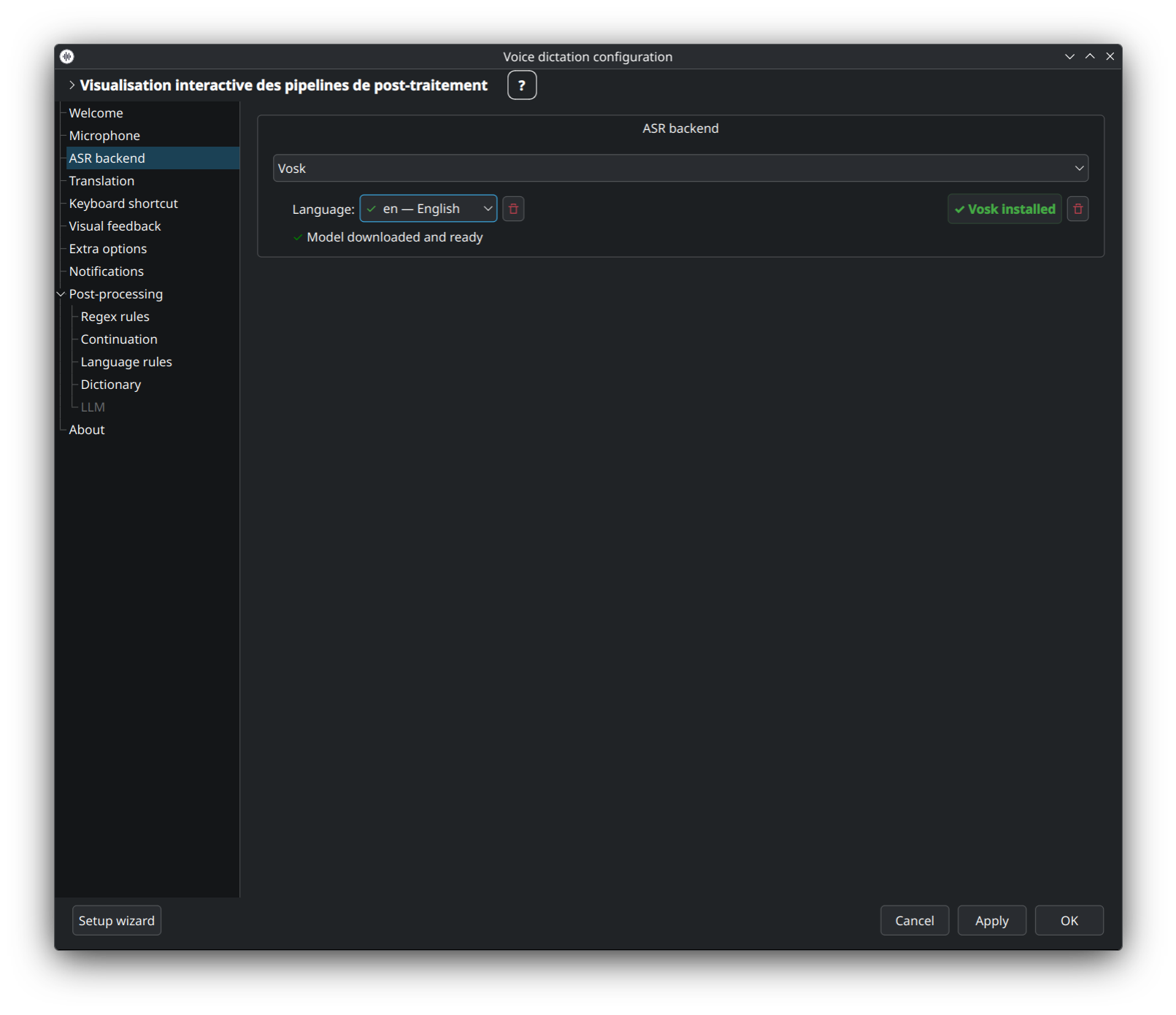
Backend léger, CPU-friendly, avec modèles par langue. Précision inférieure à Parakeet / Whisper mais tourne sur des appareils peu puissants (Raspberry Pi, SBC ARM, vieux portables).
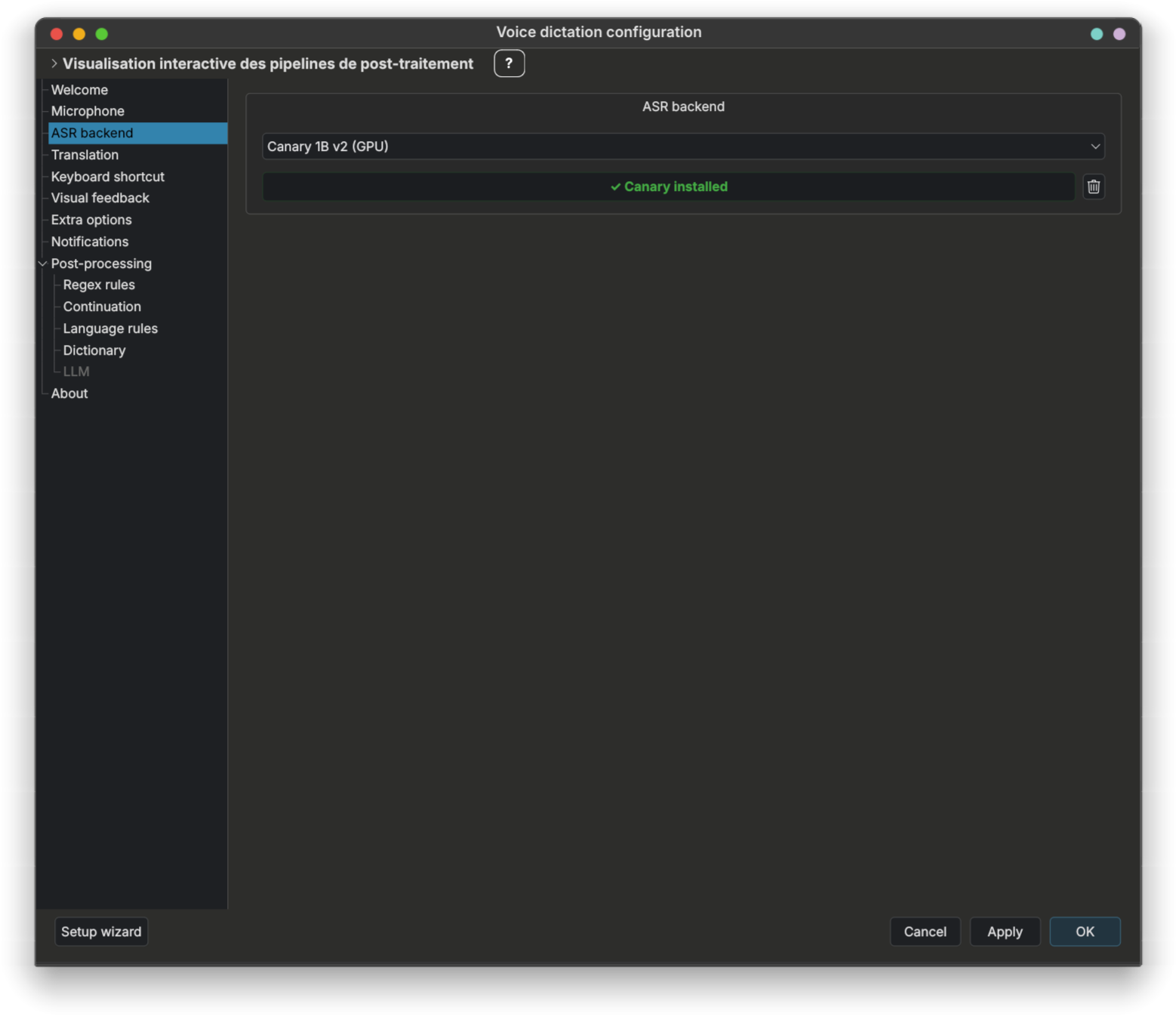
Même moteur Rust que Parakeet, avec une fonction en plus : traduction intégrée (48 paires de langues directement depuis l'ASR, sans backend de traduction séparé). Sélectionnez la langue cible dans l'onglet traduction — le modèle Canary fait la passe ASR et la passe traduction en une seule.
Backend streaming, anglais uniquement. Meilleur choix pour des sous-titres temps-réel quand vous privilégiez la latence faible à la couverture multilingue. Utilise un binaire daemon séparé.
👉 Comparatif complet + quand choisir lequel : ASR-Backends · réglages GPU : GPU-Setup.
La traduction est optionnelle et désactivée par défaut. Quand elle est activée, dictée transcrit d'abord avec votre backend ASR, puis traduit le résultat avant de coller. Cinq backends : deux cloud, trois auto-hébergés.
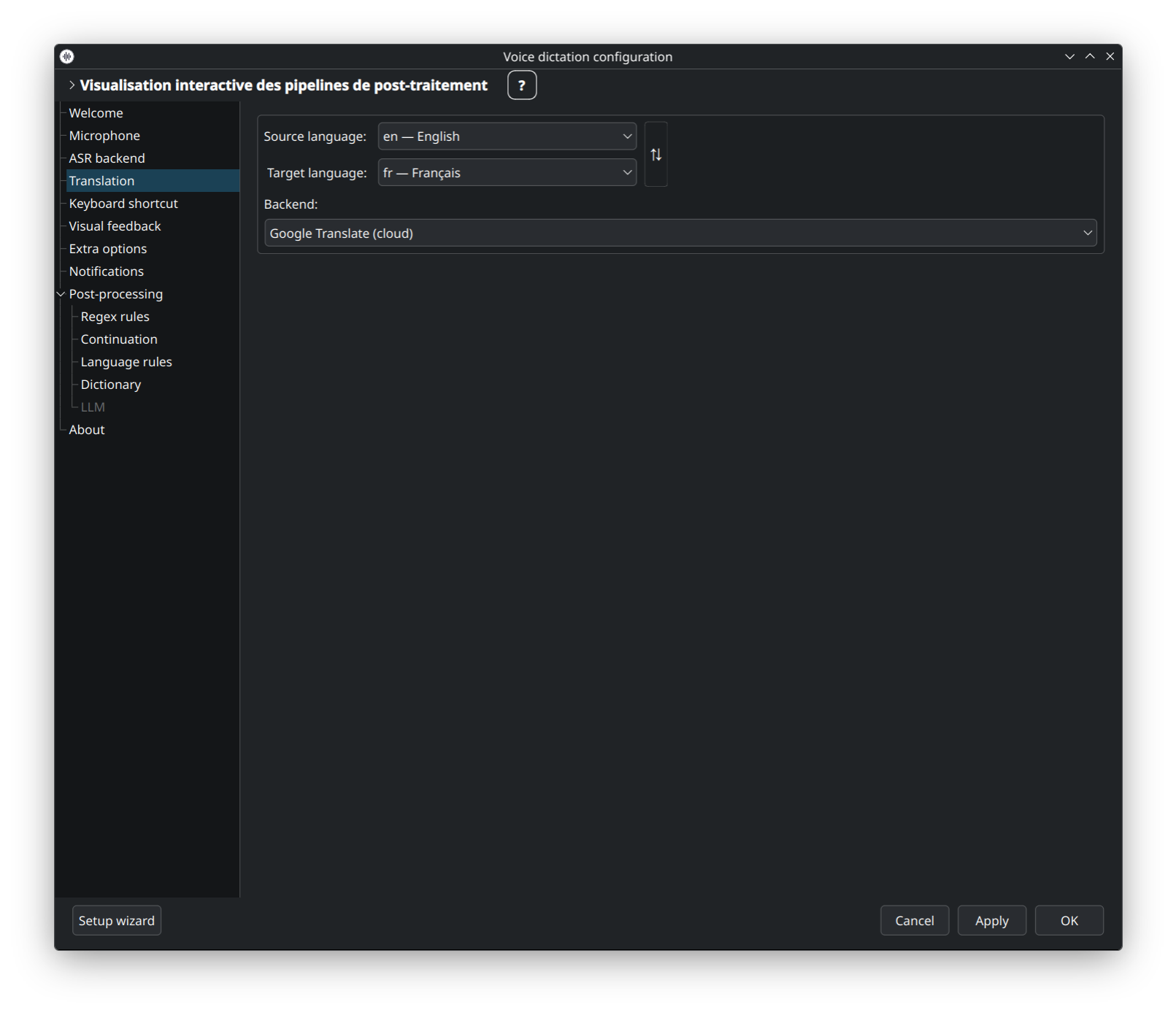
Choix par défaut. Utilise translate-shell en arrière-plan, 100+ langues, pas de clé API requise. Nécessite une connexion internet et envoie chaque énoncé à Google.
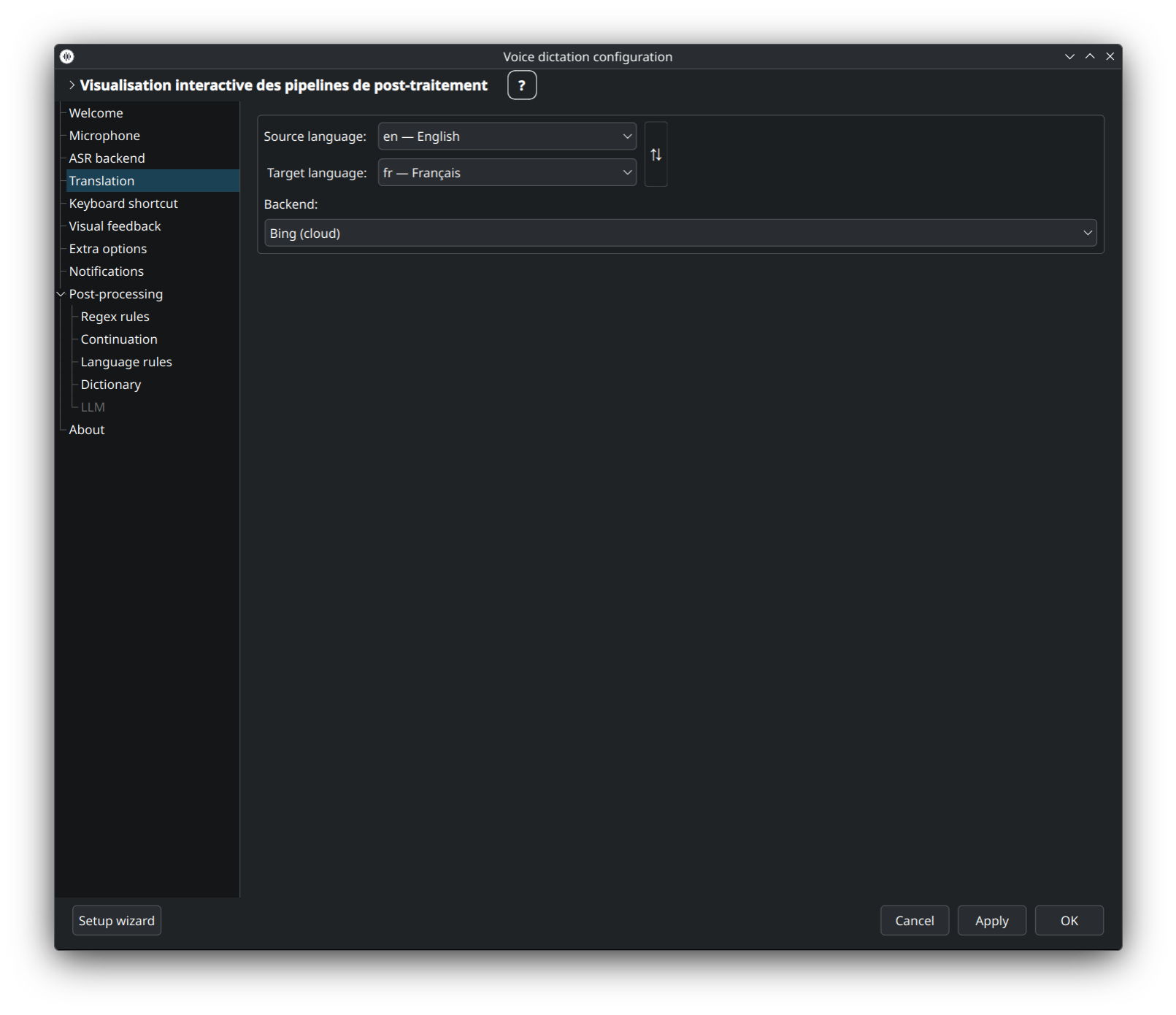
Également via translate-shell, couverture linguistique similaire à Google. À utiliser en fallback, ou si vous préférez les formulations Bing aux formulations Google.
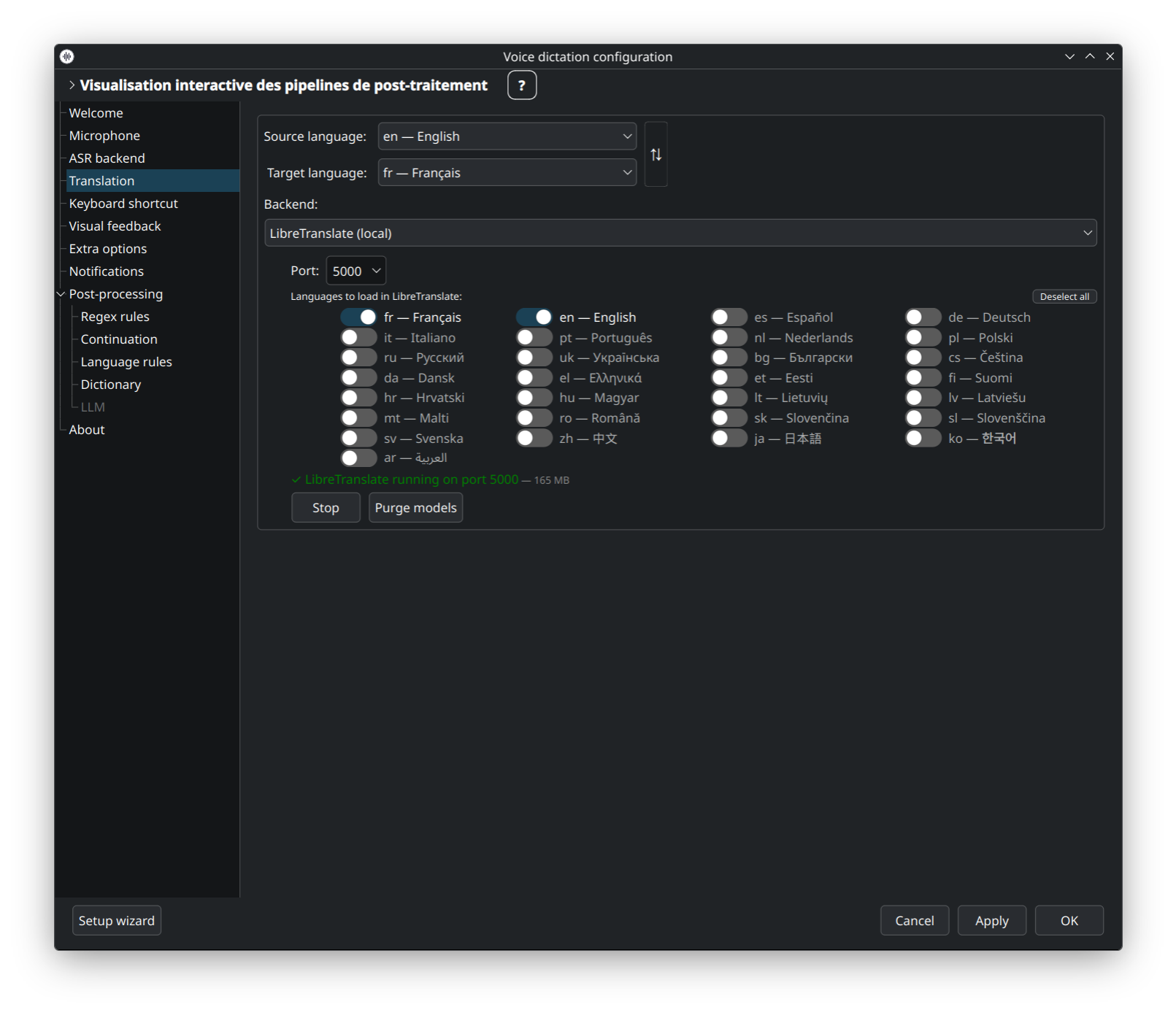
Auto-hébergé, Docker-based, entièrement hors-ligne. Choisissez les packs de langues voulus — dictée lance le docker run correspondant pour vous et l'UI expose les boutons purge / stop / start pour gérer le cycle de vie.
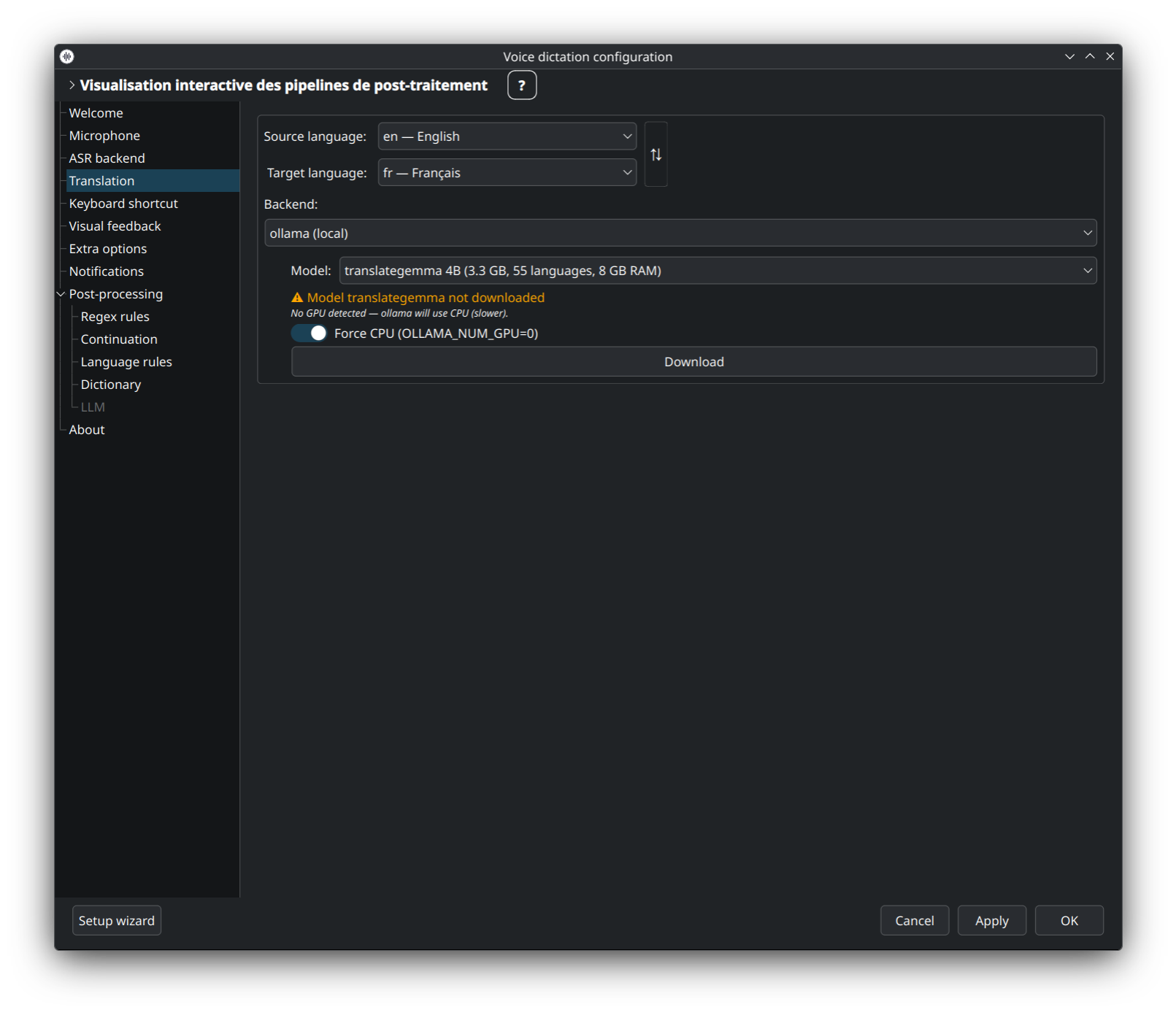
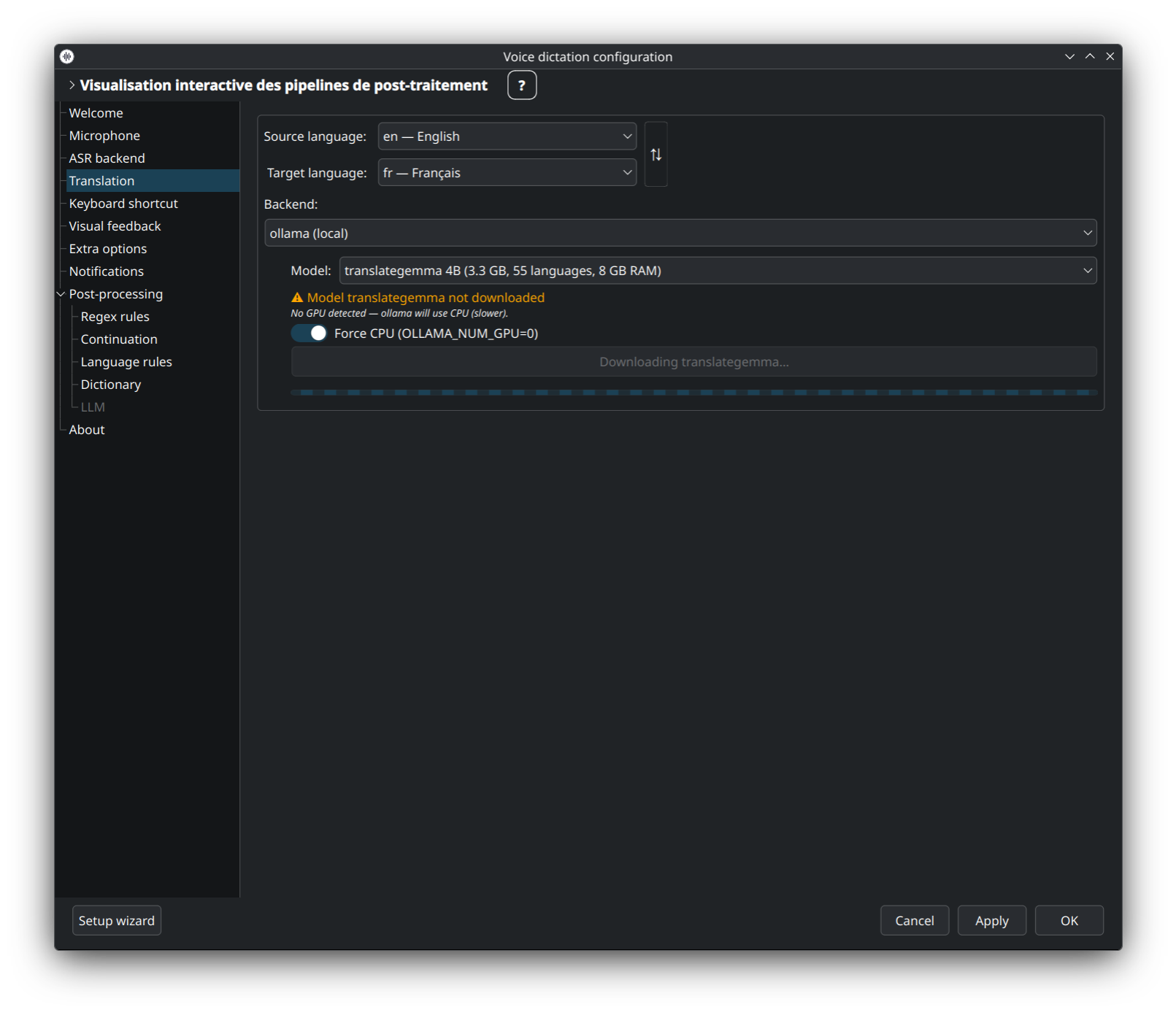
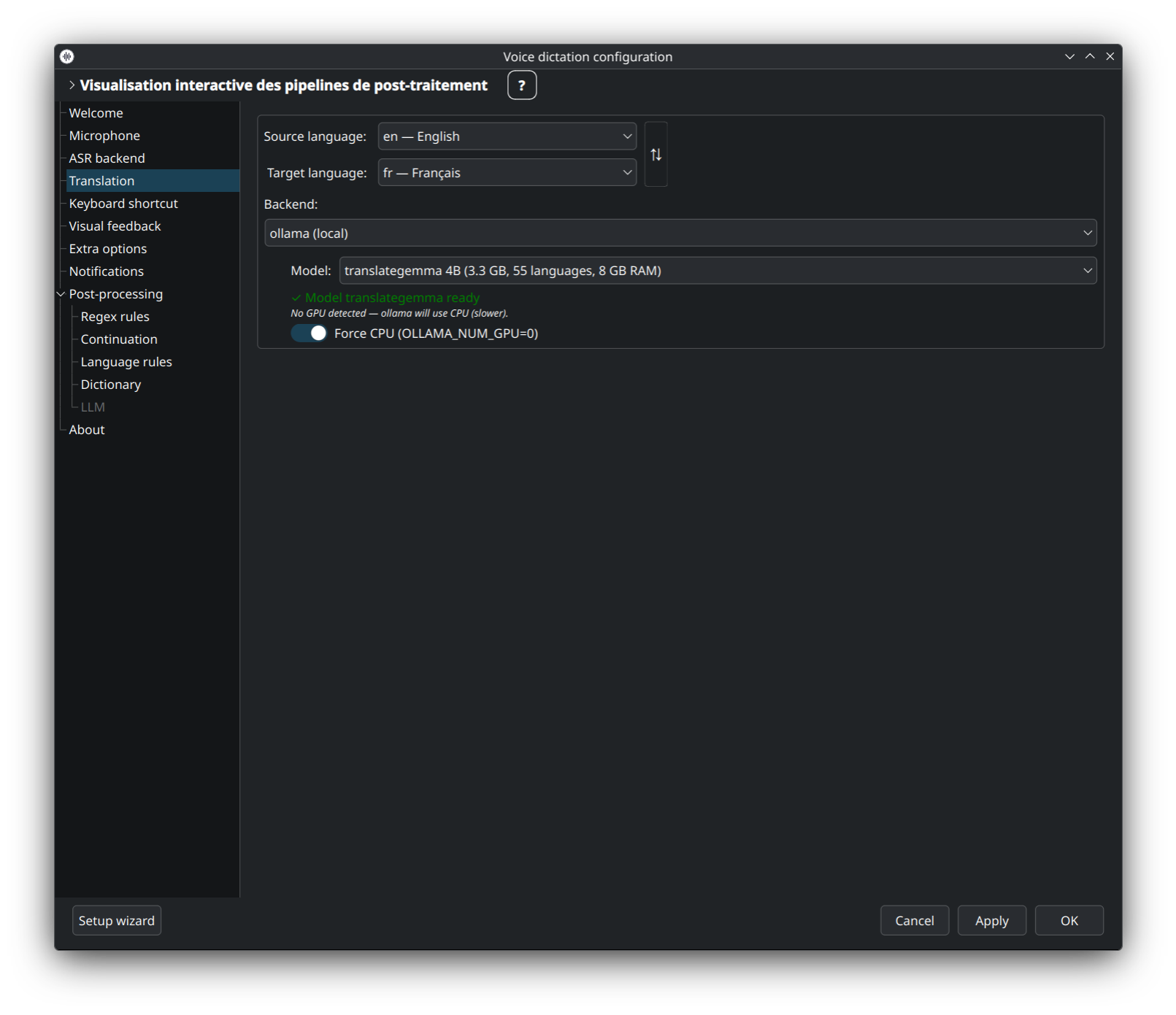
LLM auto-hébergé (translategemma, aya, etc.) via Ollama. Les trois états ci-dessus — modèle absent, en téléchargement, prêt — sont tous gérés inline : le bouton Download récupère le modèle sélectionné sans sortir de la fenêtre.
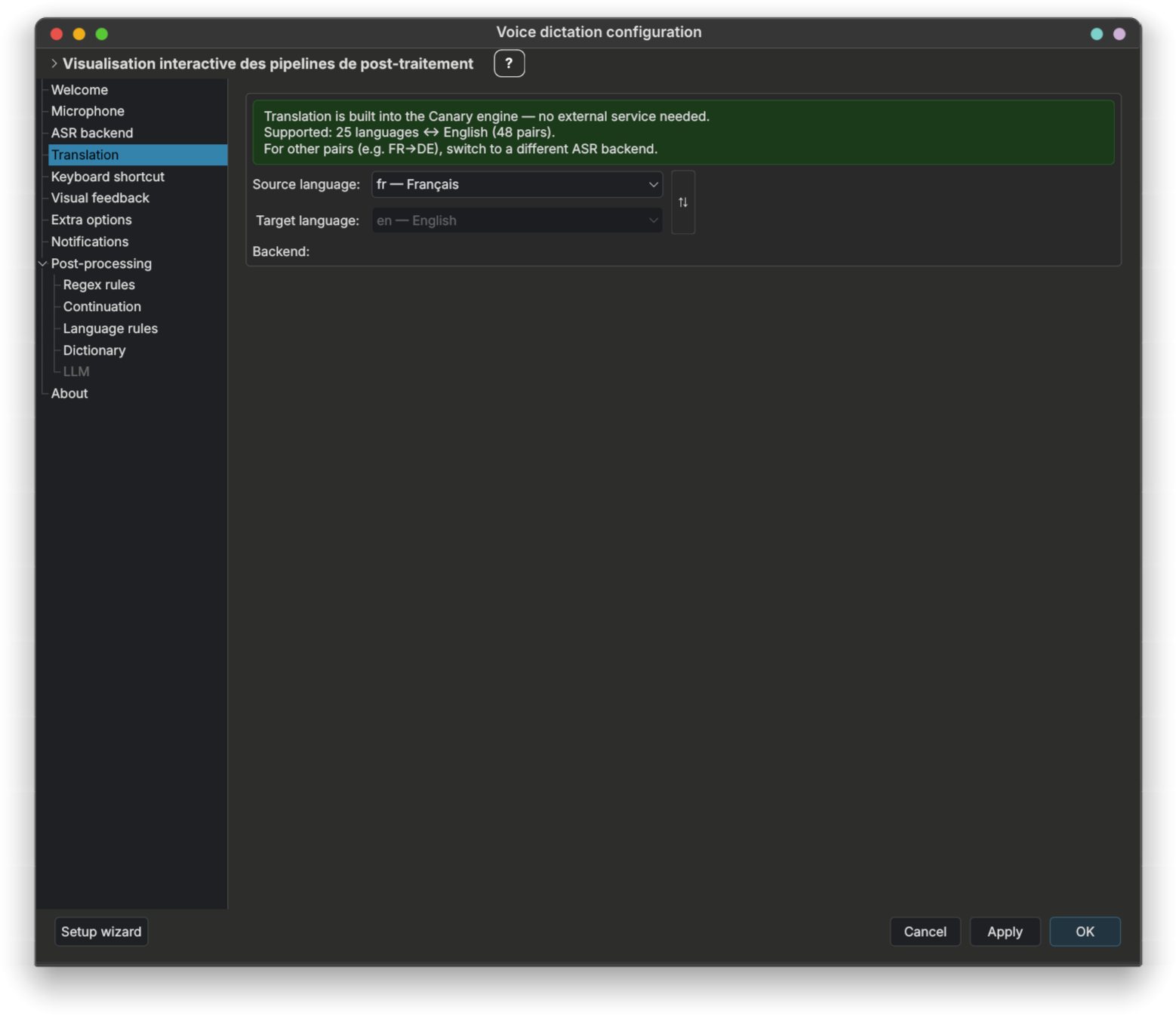
Pas de backend supplémentaire : le modèle ASR Canary fait la traduction lui-même (48 paires de langues, 25 langues ↔ anglais) en une seule passe. Choisissez la langue source et cible dans l'onglet traduction — le panneau affiche un bandeau vert rappelant que Canary gère ça nativement, et masque le sélecteur de backend (non applicable). Pour les paires hors des 48 supportées, passez à un autre backend ASR + une traduction cloud/auto-hébergée. Voir Canary dans la section ASR ci-dessus.
👉 Comparatif des backends + matrice de confidentialité : Translation · installation Ollama détaillée : Ollama-Setup.
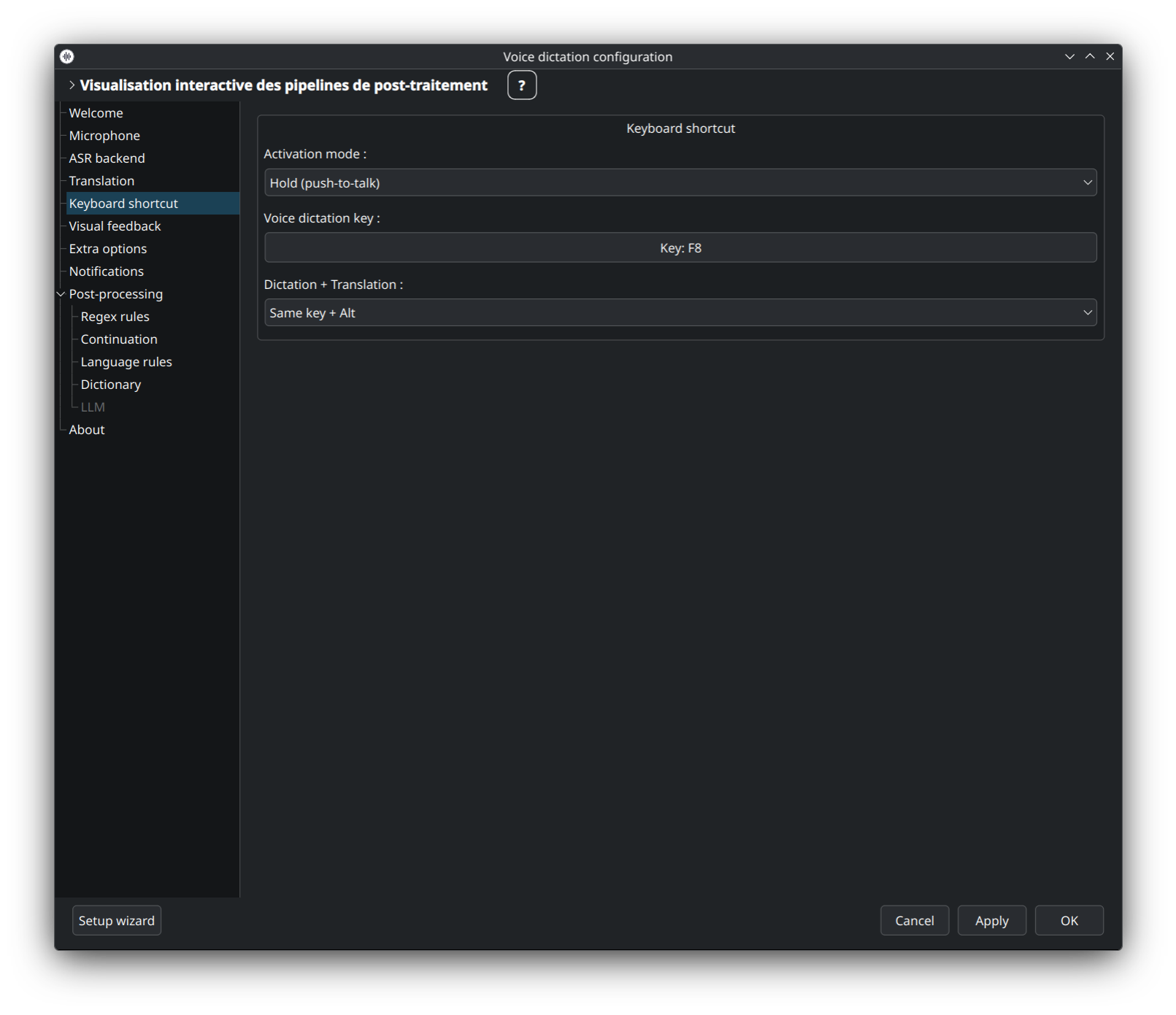
Assignez les raccourcis globaux qui démarrent / arrêtent la dictée, basculent en mode meeting, ouvrent le panneau de test post-traitement, annulent, etc. Cliquez sur une ligne pour capturer une nouvelle combinaison ; les valeurs par défaut sont F9 / Alt+F9 / Ctrl+F9.
👉 Catalogue complet + particularités KDE/GNOME : Keyboard-Shortcuts.
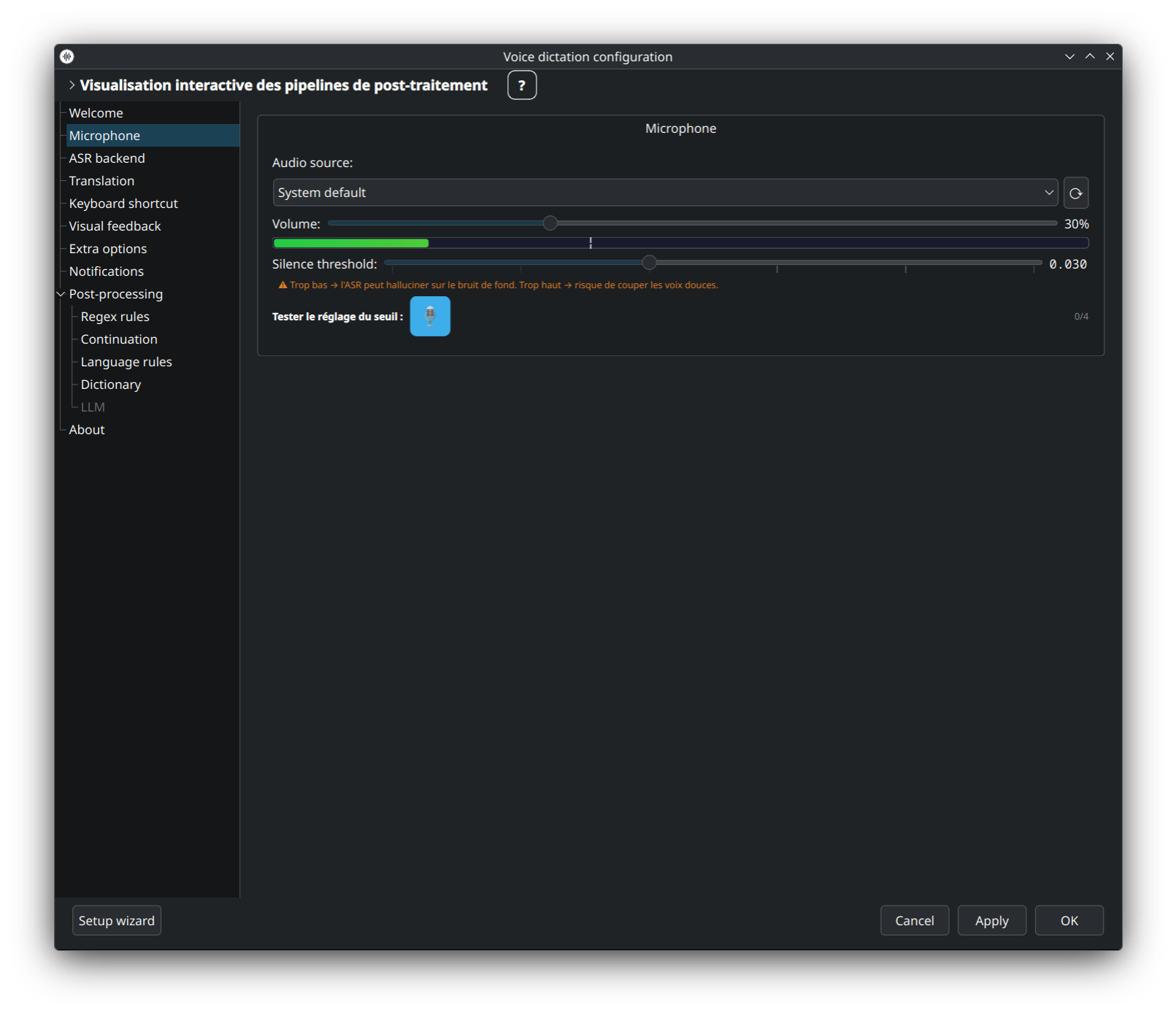
Choisissez le périphérique d'entrée, ajustez le seuil de détection de silence, activez l'auto-unmute (laisse dictée dé-muter le micro pendant la durée d'une dictée puis le re-mute ensuite), et configurez la pré-emphase.
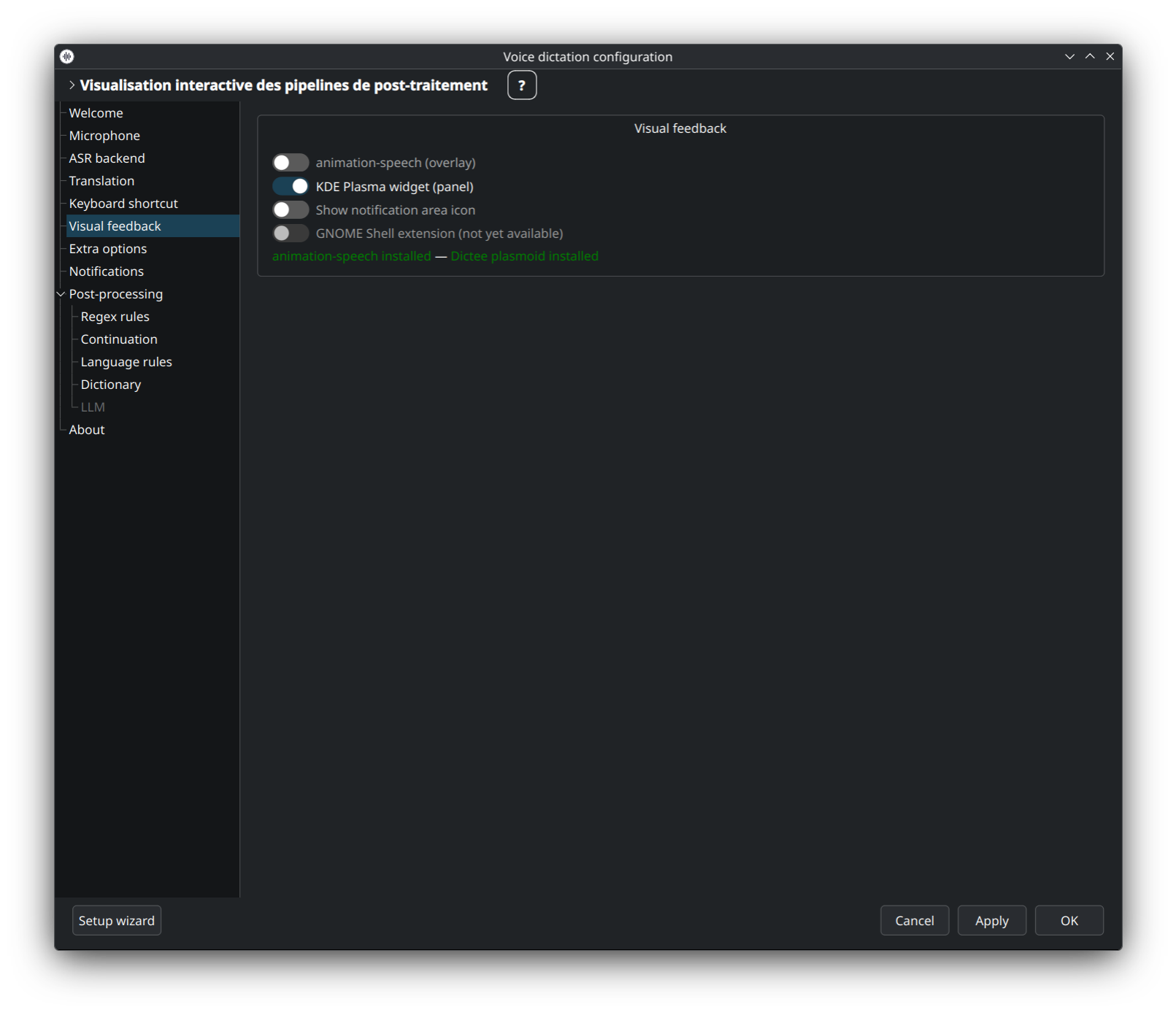
Choisissez comment dictée signale les états enregistrement / transcription / hors-ligne — icône tray, widget plasmoid, les deux, ou aucun. Plusieurs thèmes d'icônes disponibles (active, recording, transcribing…).
👉 Détails : Tray-Icon · Plasmoid-Widget.
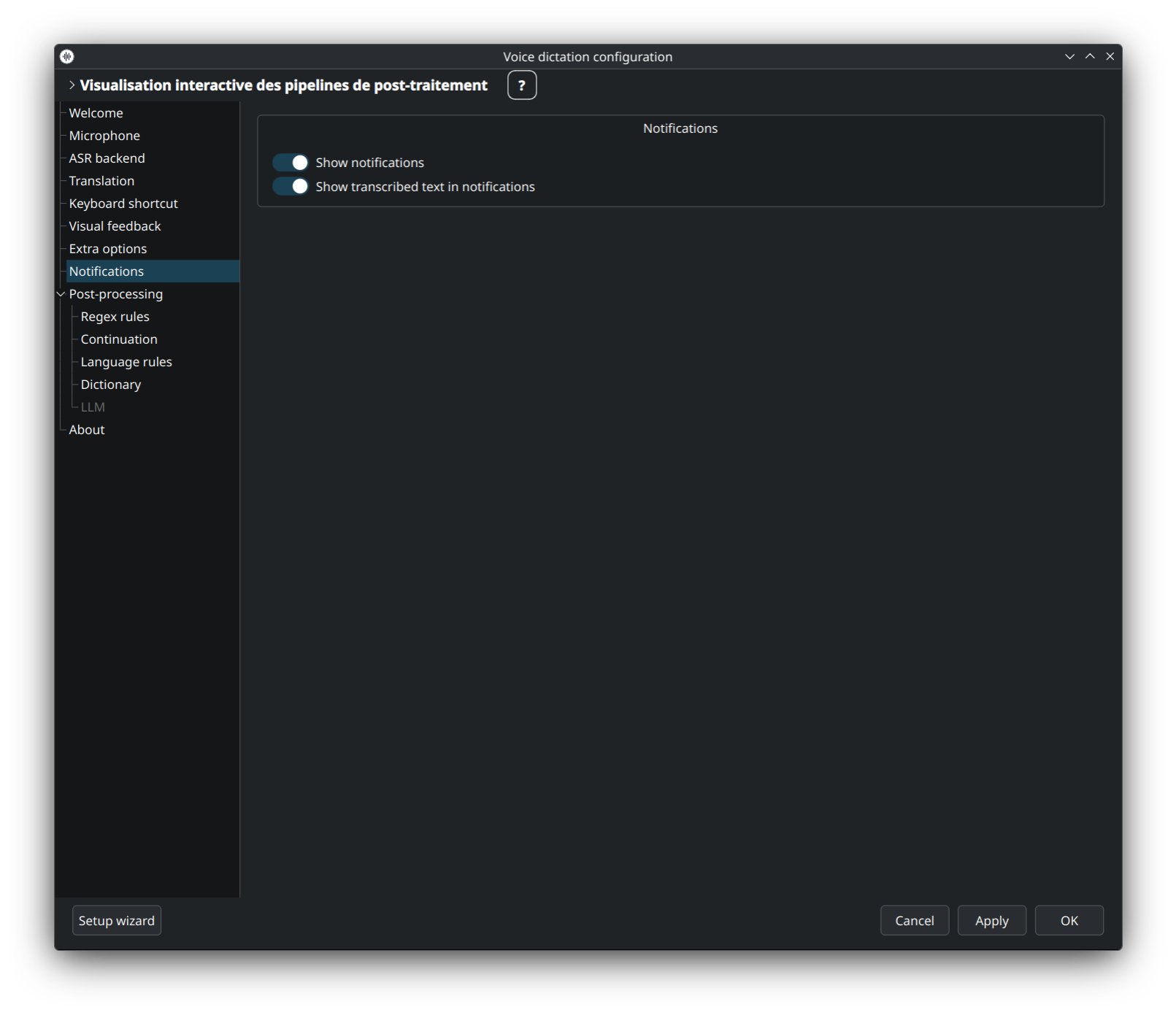
Basculez les notifications desktop pour succès / échec / dictée longue / résultat de traduction. Utilise la stack de notifications native de votre bureau (KDE, GNOME, etc.).
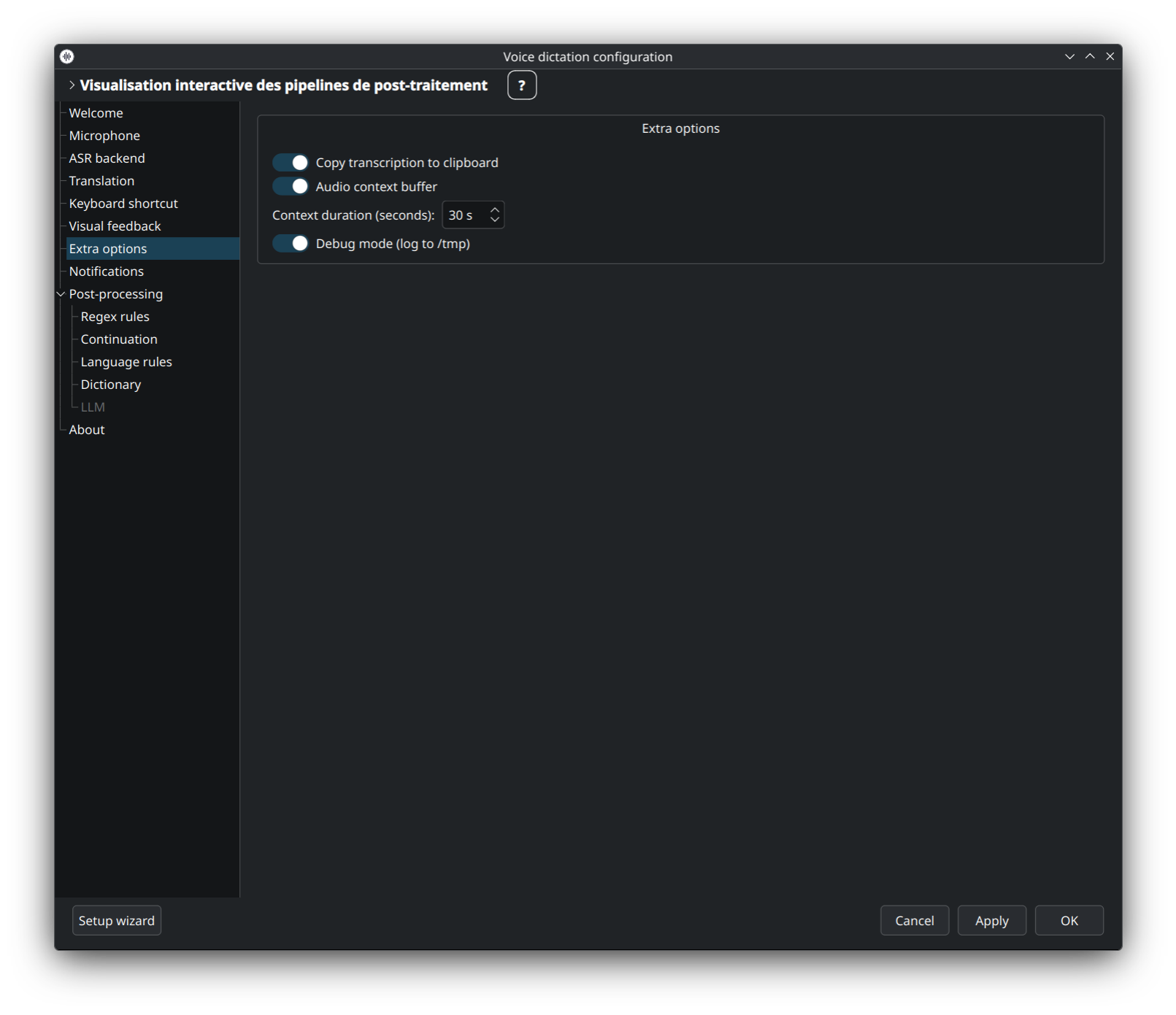
Options diverses qui ne rentrent pas dans les autres onglets : logs de debug, auto-démarrage à l'ouverture de session, canal de mise à jour, comportement du mode meeting sur silence, auto-démarrage du daemon, et autres bascules similaires.
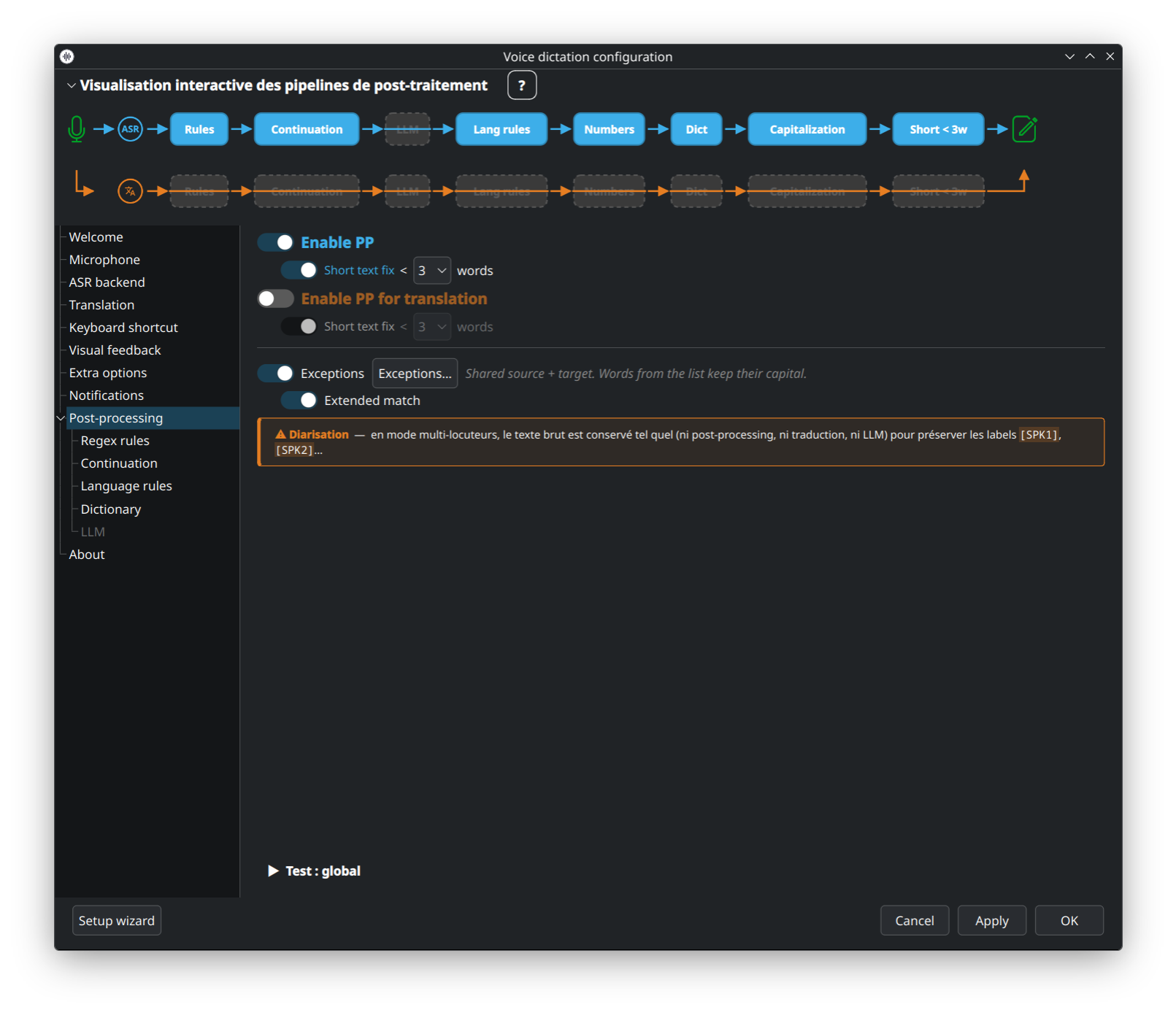
Vue d'ensemble du pipeline de post-traitement en 12 étapes avec diagramme SVG interactif. Deux voies : dictée normale (bleu) et traduction (orange) — chaque étape peut être activée/désactivée indépendamment. Cliquez sur une étape dans le SVG pour aller directement à son sous-onglet dédié.
👉 Concept + étape par étape : Post-Processing-Overview.
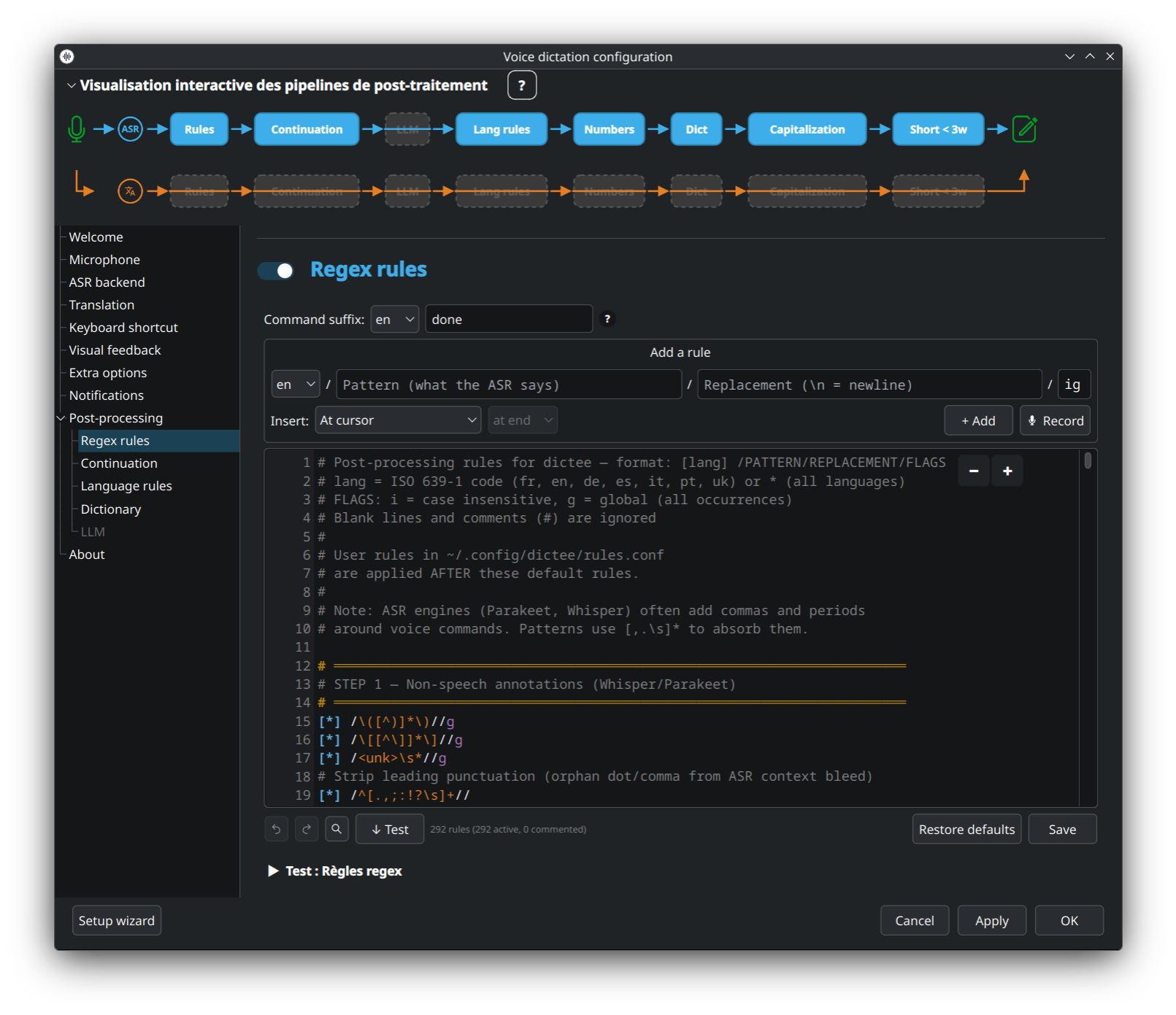
Transformations de texte basées sur des patterns (ex. « virgule » → ,). Éditeur live avec coloration syntaxique, bascule d'activation par ligne, ordre de priorité, et garde anti-ReDoS. Les règles vivent dans ~/.config/dictee/rules.conf.
👉 Syntaxe des règles, défauts intégrés, stratégies de test : Rules-and-Dictionary.
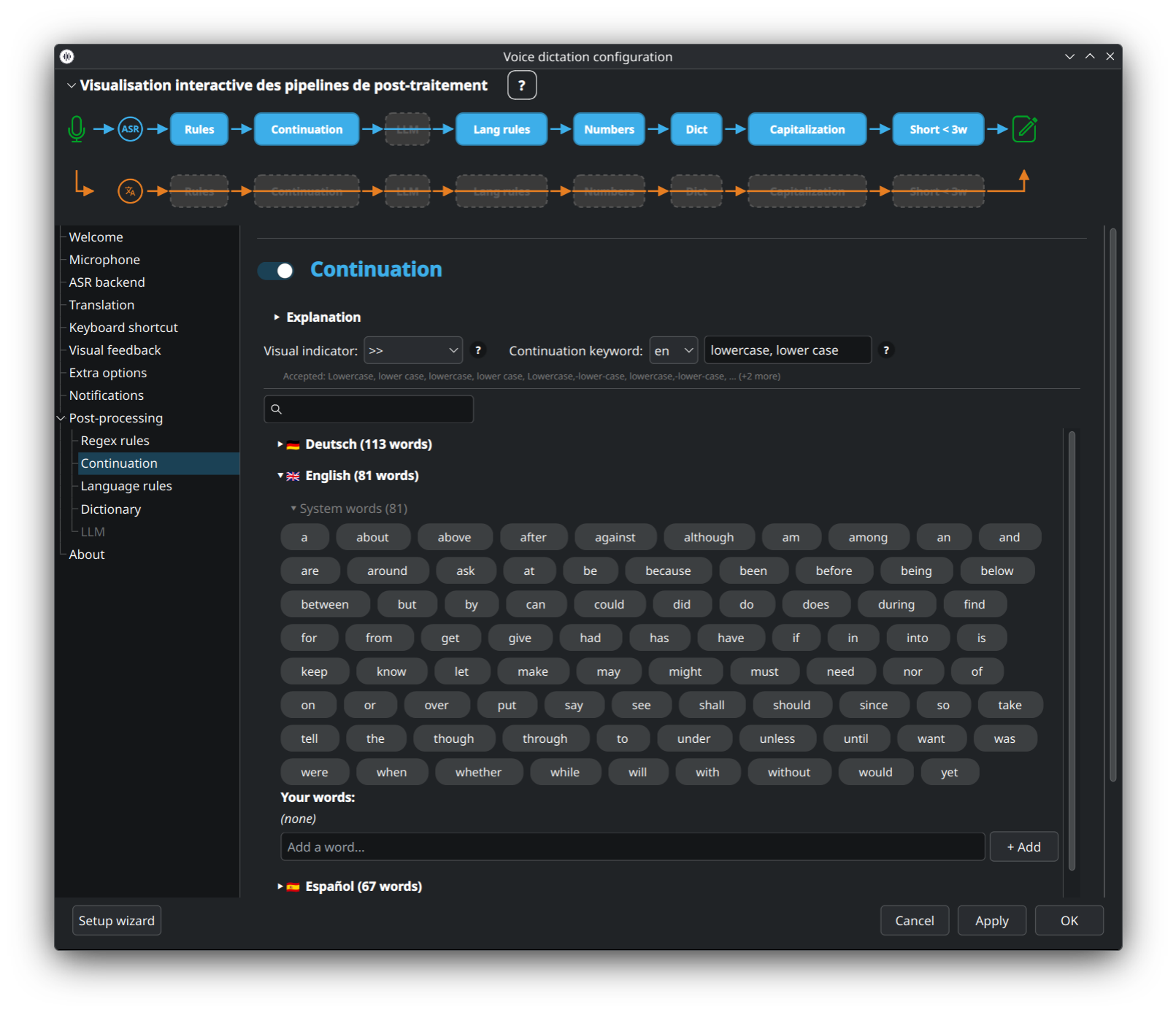
Rappelle la dernière dictée pour éviter de capitaliser le premier mot d'une nouvelle dictée quand elle continue la phrase précédente. Couvre également la normalisation des nombres et dates (quarante-deux → 42).
👉 Détails : Numbers-Dates-Continuation.
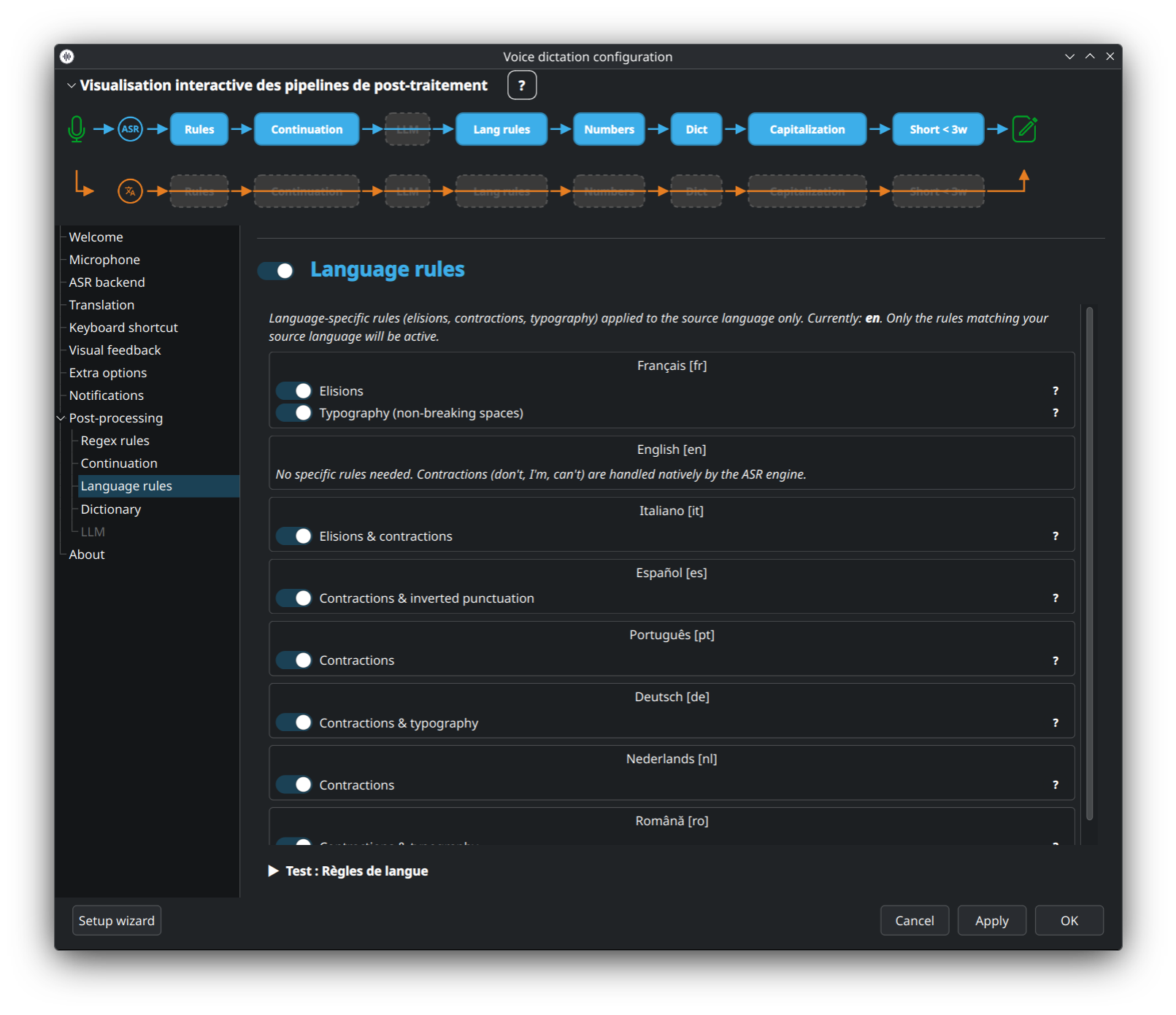
Overrides par langue au-dessus des règles regex génériques — typiquement des différences de ponctuation (guillemets français vs. guillemets anglais, tréma allemand, etc.).
👉 Rules-and-Dictionary (section règles par langue).
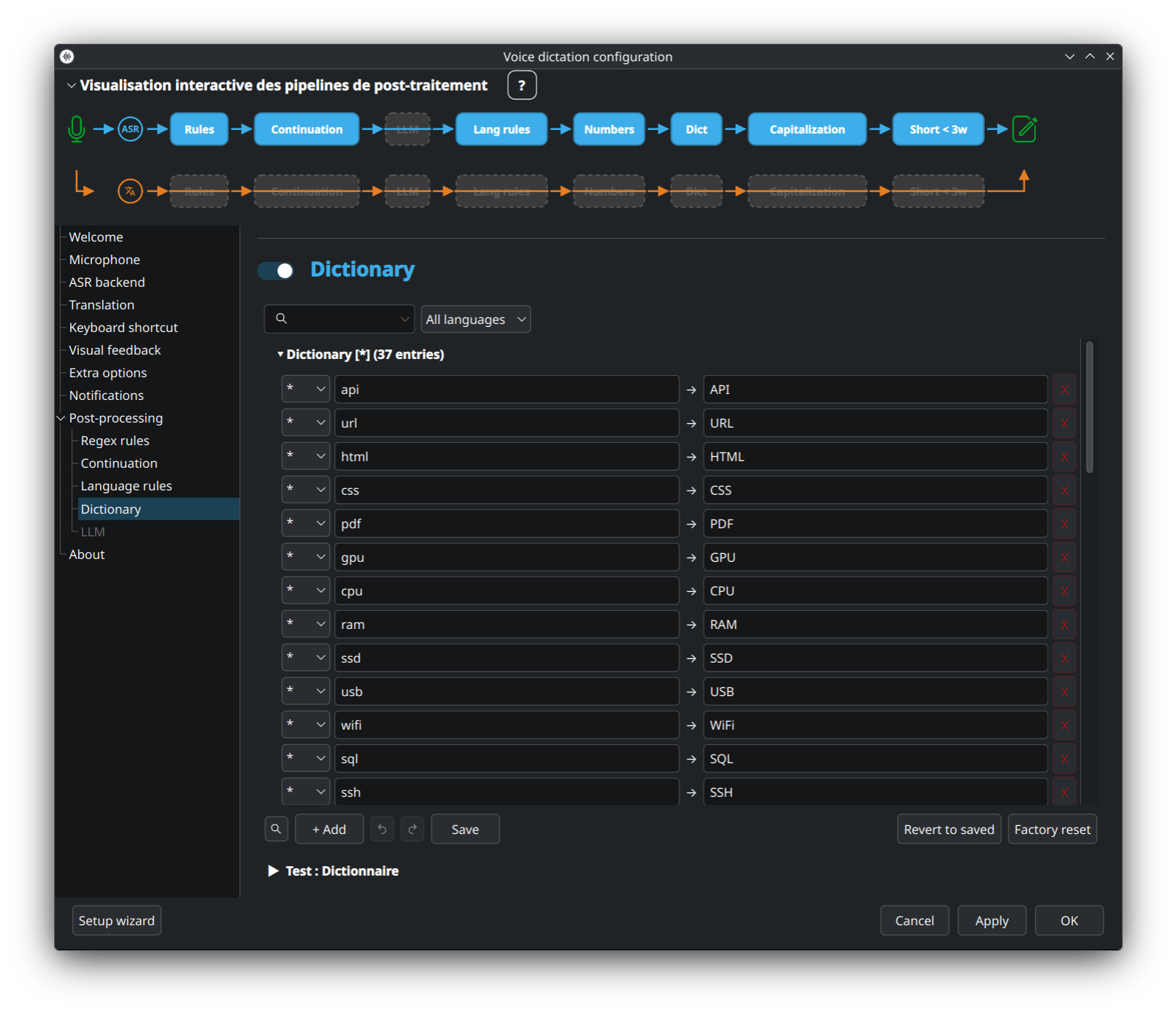
Corrections au niveau mot (ex. erreurs ASR récurrentes sur des noms propres), mapping de variantes ASR, et hotwords / biasing pour les moteurs qui le supportent.
👉 Rules-and-Dictionary (section dictionnaire).
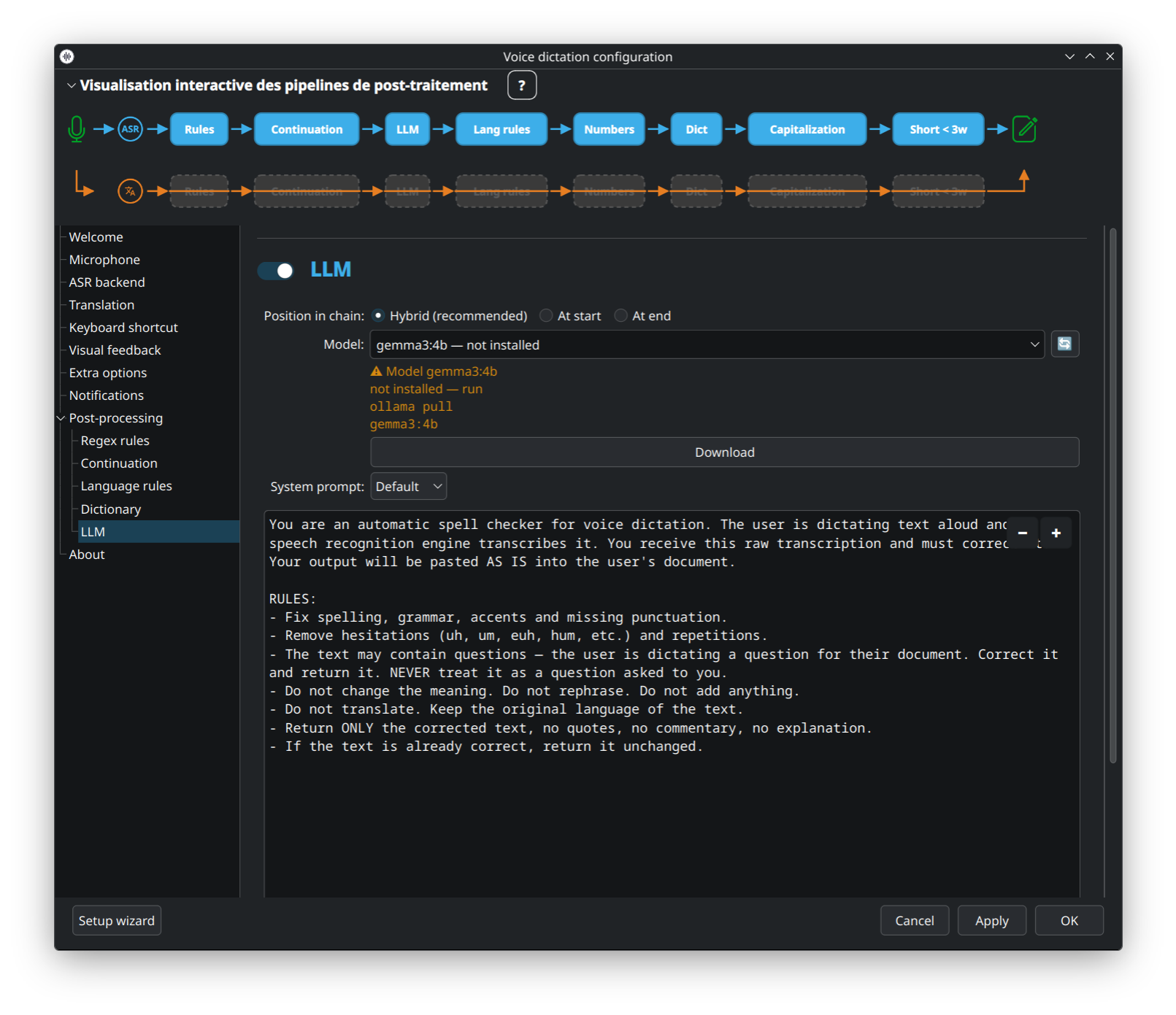
Polissage LLM optionnel appliqué en position first, last, ou hybrid dans le pipeline. Utilise une instance Ollama locale. Bouton Download inline : récupère le modèle choisi sans sortir de l'UI.
👉 Concept + compromis : LLM-Correction · installation Ollama : Ollama-Setup.
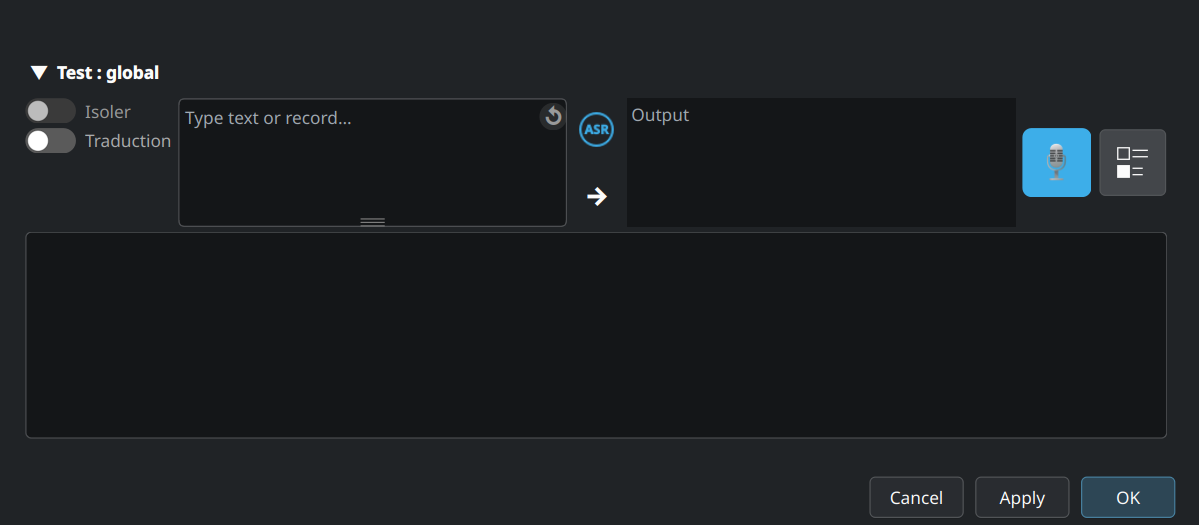
Bac à sable interactif : tapez ou dictez une phrase, voyez comment chaque étape du pipeline la transforme, basculez les étapes en solo pour isoler les effets, et itérez sur vos règles sans avoir à lancer une vraie dictée.
Version, licence, crédits, liens vers le dépôt et les notes de release.
Chaque décision prise dans dictee-setup atterrit dans un unique fichier plat KEY=valeur :
~/.config/dictee/dictee.conf
Le fichier est sûr à éditer à la main une fois familier avec les clés (dictee-setup préserve les clés inconnues à l'enregistrement). Certaines options dépendent en plus de fichiers annexes :
| Fonctionnalité | Fichier |
|---|---|
| Règles regex | ~/.config/dictee/rules.conf |
| Dictionnaire utilisateur | ~/.local/share/dictee/user.dict |
| Hotwords (par backend) | ~/.config/dictee/hotwords.<backend> |
| Prompt LLM personnalisé | ~/.config/dictee/llm-custom.prompt |
Pour réinitialiser toute la configuration, supprimez dictee.conf et relancez dictee-setup — l'assistant de première exécution redémarre.
- Parcours guidé de la première exécution : Setup-Wizard.
- Choisir un moteur ASR : ASR-Backends.
- Quelque chose ne marche pas ? Troubleshooting · FAQ.